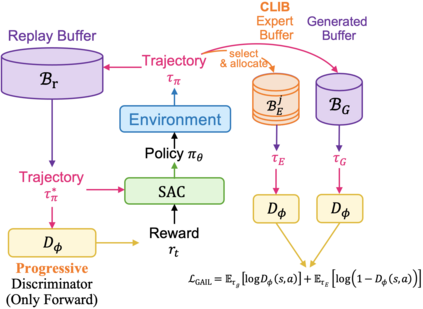
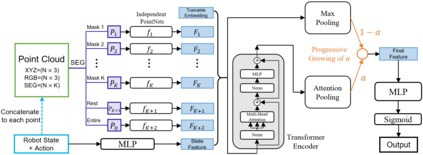
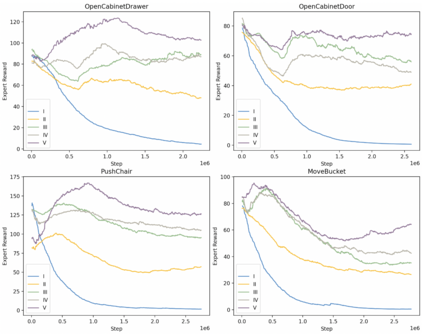
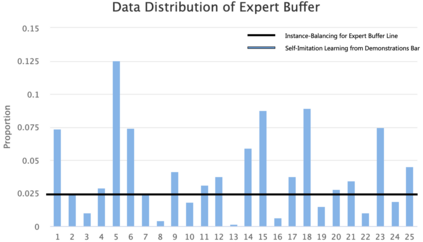
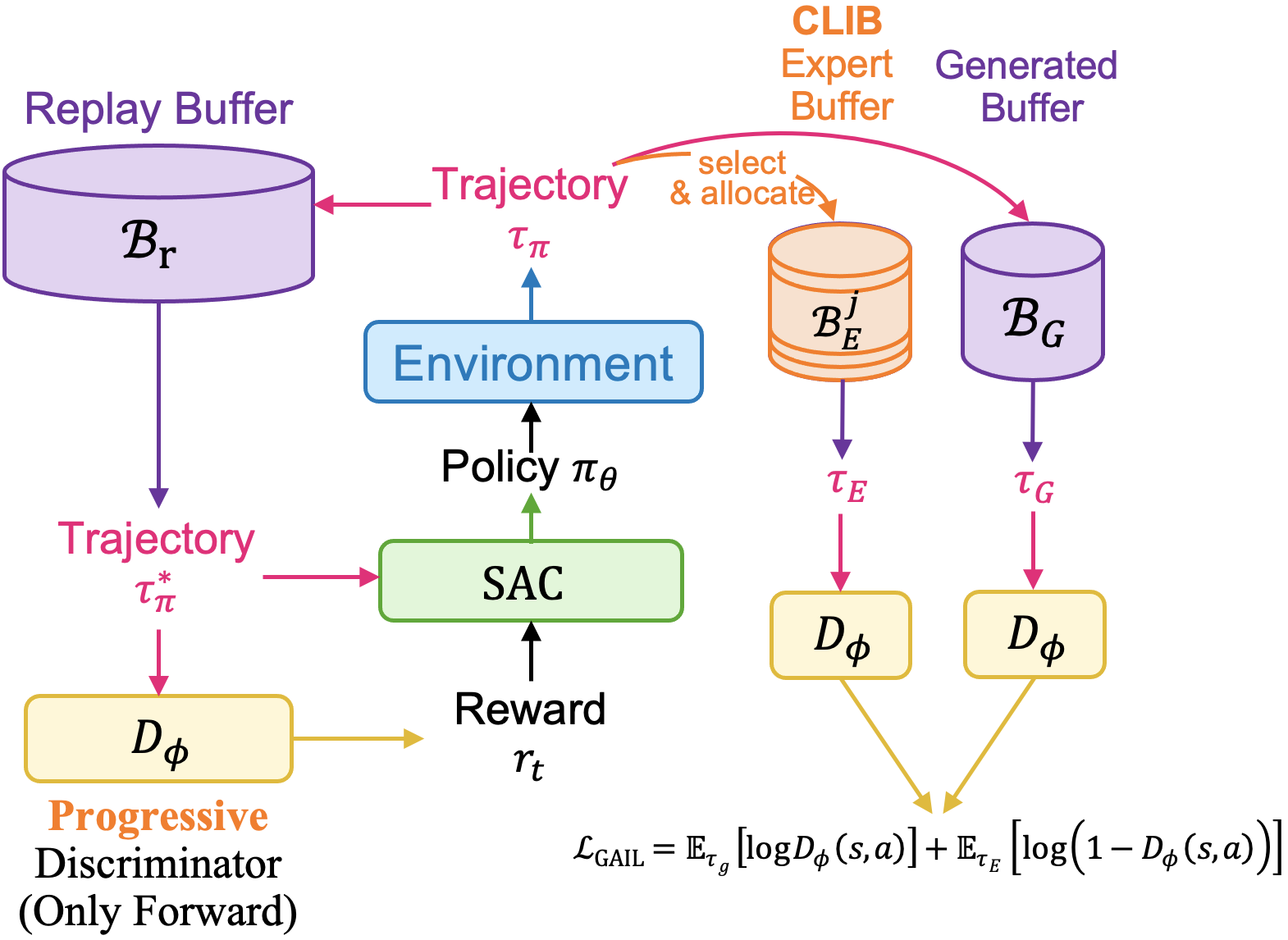
Generalizable object manipulation skills are critical for intelligent and multi-functional robots to work in real-world complex scenes. Despite the recent progress in reinforcement learning, it is still very challenging to learn a generalizable manipulation policy that can handle a category of geometrically diverse articulated objects. In this work, we tackle this category-level object manipulation policy learning problem via imitation learning in a task-agnostic manner, where we assume no handcrafted dense rewards but only a terminal reward. Given this novel and challenging generalizable policy learning problem, we identify several key issues that can fail the previous imitation learning algorithms and hinder the generalization to unseen instances. We then propose several general but critical techniques, including generative adversarial self-imitation learning from demonstrations, progressive growing of discriminator, and instance-balancing for expert buffer, that accurately pinpoints and tackles these issues and can benefit category-level manipulation policy learning regardless of the tasks. Our experiments on ManiSkill benchmarks demonstrate a remarkable improvement on all tasks and our ablation studies further validate the contribution of each proposed technique.
翻译:通用的物体操纵技能对于智能和多功能机器人在现实世界复杂场景中工作至关重要。尽管最近加强学习工作取得了进展,但学习一个通用的操纵政策仍然非常困难,该政策能够处理几何形形形色色的分解对象。在这项工作中,我们通过模仿学习,以任务不可知的方式解决这一类别级物体操纵政策学习问题,我们不承担手工制作的密集奖赏,而只承担终极奖赏。鉴于这个新颖和具有挑战性的通用政策学习问题,我们找出了几个关键问题,这些问题可能使先前的模仿学习算法失败,阻碍将常规化为看不见的实例。我们然后提出了若干一般性但重要的技术,包括从演示中学习自缩自定义、逐步增加歧视者、为专家缓冲提供例平衡,从而准确地定位和处理这些问题,并有利于分类操纵政策学习,而不论任务如何。我们关于曼斯证明基准的实验表明所有任务都取得了显著的改进,而且我们的消化研究进一步验证了每一项拟议技术的贡献。