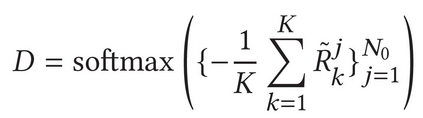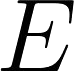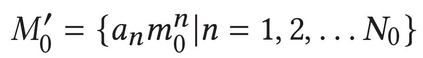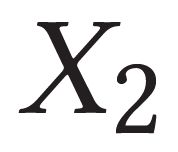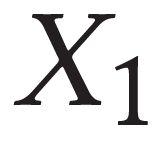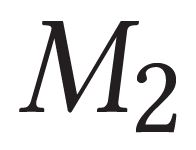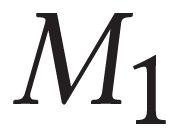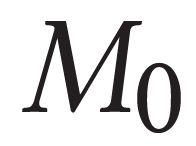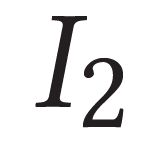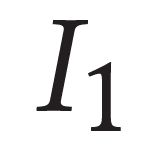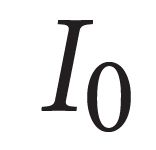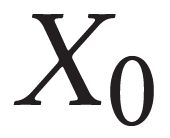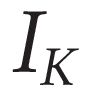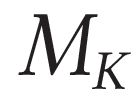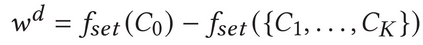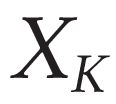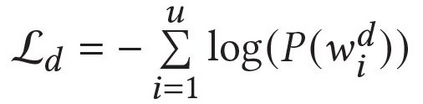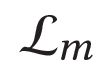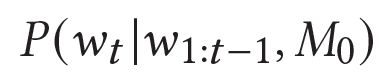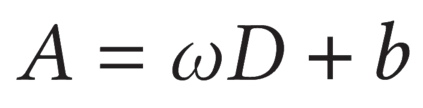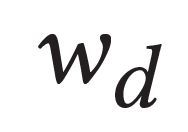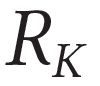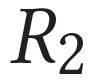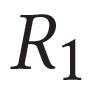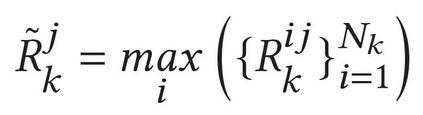Describing images using natural language is widely known as image captioning, which has made consistent progress due to the development of computer vision and natural language generation techniques. Though conventional captioning models achieve high accuracy based on popular metrics, i.e., BLEU, CIDEr, and SPICE, the ability of captions to distinguish the target image from other similar images is under-explored. To generate distinctive captions, a few pioneers employ contrastive learning or re-weighted the ground-truth captions, which focuses on one single input image. However, the relationships between objects in a similar image group (e.g., items or properties within the same album or fine-grained events) are neglected. In this paper, we improve the distinctiveness of image captions using a Group-based Distinctive Captioning Model (GdisCap), which compares each image with other images in one similar group and highlights the uniqueness of each image. In particular, we propose a group-based memory attention (GMA) module, which stores object features that are unique among the image group (i.e., with low similarity to objects in other images). These unique object features are highlighted when generating captions, resulting in more distinctive captions. Furthermore, the distinctive words in the ground-truth captions are selected to supervise the language decoder and GMA. Finally, we propose a new evaluation metric, distinctive word rate (DisWordRate) to measure the distinctiveness of captions. Quantitative results indicate that the proposed method significantly improves the distinctiveness of several baseline models, and achieves the state-of-the-art performance on both accuracy and distinctiveness. Results of a user study agree with the quantitative evaluation and demonstrate the rationality of the new metric DisWordRate.
翻译:使用自然语言的描述图像被广泛称为图像说明,由于计算机视觉和自然语言生成技术的发展,这取得了持续的进展。虽然传统标题模型在流行度量的基础上(即BLEU、CIDER和SPICE)实现了高度精准性,但用于区分目标图像和其他类似图像的字幕能力却未得到充分探讨。为了生成独特的字幕,少数先驱者采用了以单一输入图像为焦点的地面图解字幕,这已经取得了持续的进展。然而,类似图像组中的对象(例如R,同一相册或细度事件中的项目或属性)之间的关系被忽略了。在本文件中,我们利用基于集团的突出度度量模型(Gdiscap)来改进图像的特性,该模型将每个图像与其他组中的图像进行比较,并突出每个图像的独特性。我们提议了一个基于集团的记忆关注(GMA)模块,该模块存储了一个在图像组中具有独特性特征的物体(i.i.a. 以低比值的直径直径直径的直径直径直径直径直径直径直径直径直径直径直径直径直径直径直径直径直径直径直径直径直径直径直径直径直径直径直径直径直径直径直的图像直径直径直的图像直径直的图像标的图像直径直径直径直径直的图像直的图像段段段段距值,这些直径直径直的图像段段段直的图像段段段段段段段直路路段直路段直路段距,这些直径直径直径直径直径直径直径直路。这些直的图像直的直的图像直的图像显示的图像显示的图像显示。