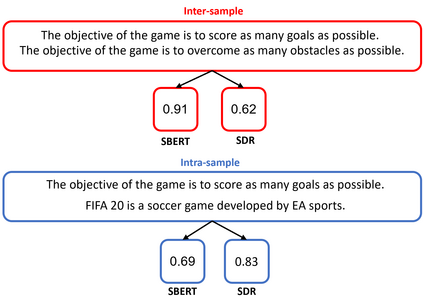
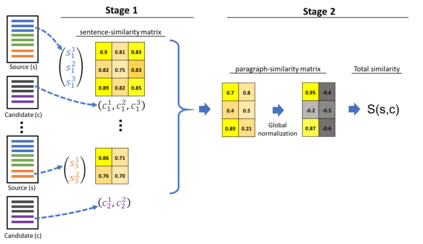
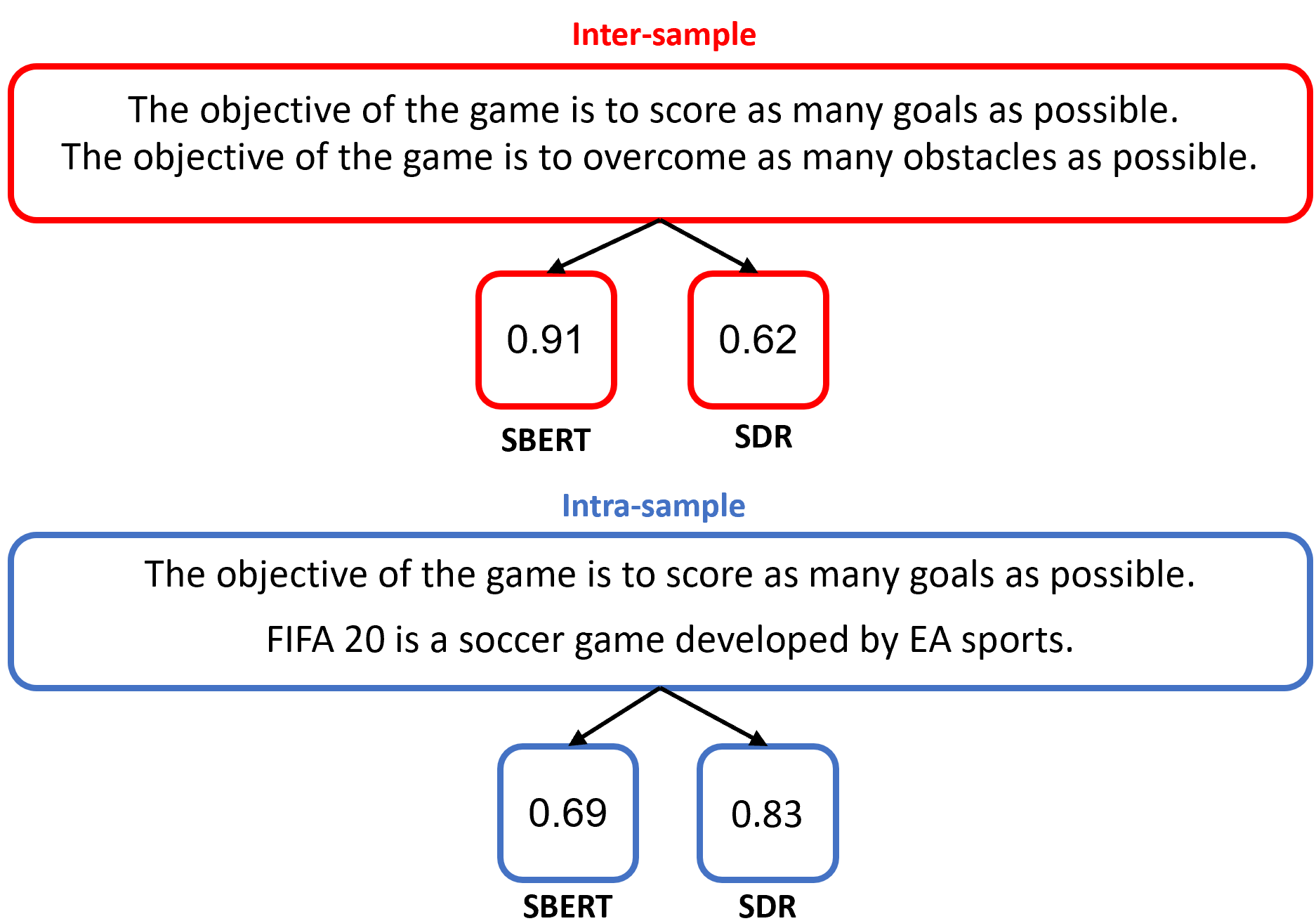
We present a novel model for the problem of ranking a collection of documents according to their semantic similarity to a source (query) document. While the problem of document-to-document similarity ranking has been studied, most modern methods are limited to relatively short documents or rely on the existence of "ground-truth" similarity labels. Yet, in most common real-world cases, similarity ranking is an unsupervised problem as similarity labels are unavailable. Moreover, an ideal model should not be restricted by documents' length. Hence, we introduce SDR, a self-supervised method for document similarity that can be applied to documents of arbitrary length. Importantly, SDR can be effectively applied to extremely long documents, exceeding the 4,096 maximal token limits of Longformer. Extensive evaluations on large document datasets show that SDR significantly outperforms its alternatives across all metrics. To accelerate future research on unlabeled long document similarity ranking, and as an additional contribution to the community, we herein publish two human-annotated test sets of long documents similarity evaluation. The SDR code and datasets are publicly available.
翻译:我们提出了一个根据文件的语义相似性对文件进行分类问题的新模式。虽然已经研究了文件到文件的相似性排序问题,但大多数现代方法仅限于相对短的文件,或依赖“地面真相”相似性标签的存在。然而,在大多数常见的实际情况中,相似性排名是一个不受监督的问题,因为没有相似性标签。此外,理想模式不应受到文件长度的限制。因此,我们引入了特别提款权,一种可适用于任意长度文件的自我监督的文件相似性方法。重要的是,特别提款权可以有效地适用于极为长的文件,超过长征4,096个最高象征性限制。对大型文件数据集的广泛评价表明,特别提款权在所有指标中大大超越了其替代标准。为了加速今后对未贴标签的长期文件相似性排序的研究,并作为对社区的额外贡献,我们在此出版两套具有附加说明的长类似性文件的测试。特别提款权代码和数据集是公开的。