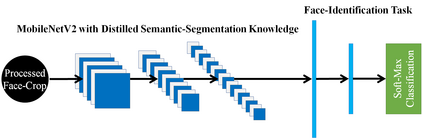
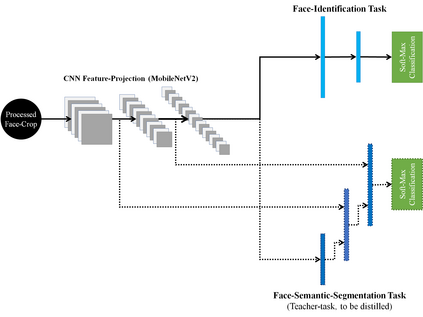
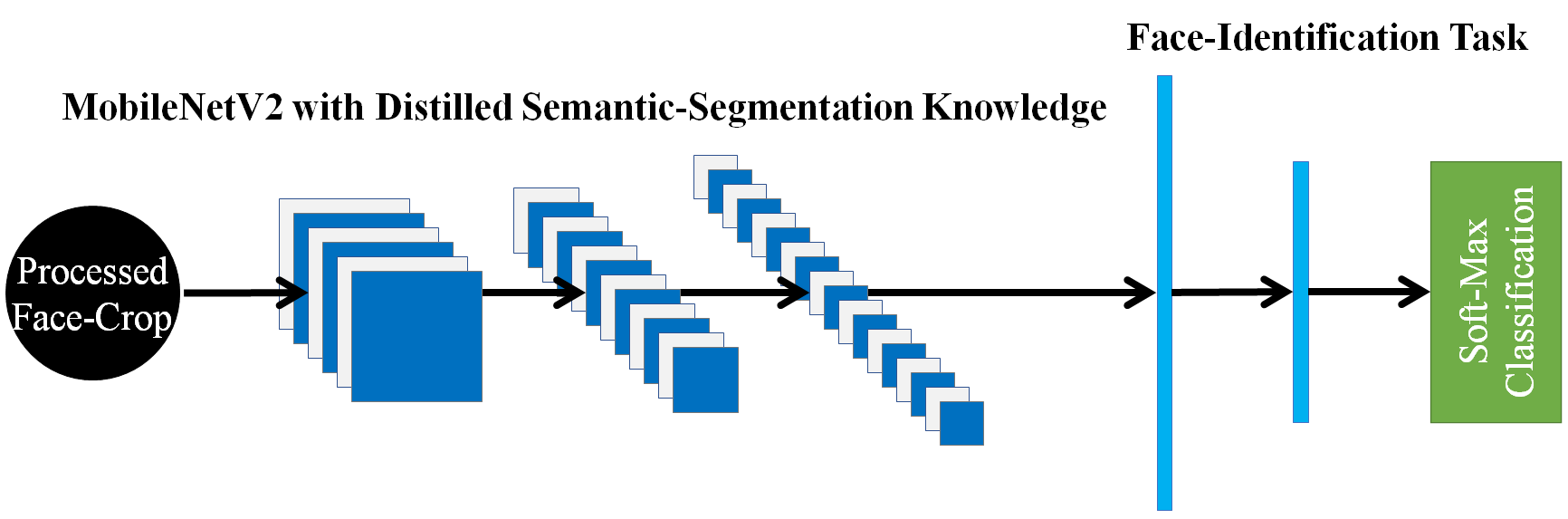
This paper demonstrates a novel approach to improve face-recognition pose-invariance using semantic-segmentation features. The proposed Seg-Distilled-ID network jointly learns identification and semantic-segmentation tasks, where the segmentation task is then "distilled" (MobileNet encoder). Performance is benchmarked against three state-of-the-art encoders on a publicly available data-set emphasizing head-pose variations. Experimental evaluations show the Seg-Distilled-ID network shows notable robustness benefits, achieving 99.9% test-accuracy in comparison to 81.6% on ResNet-101, 96.1% on VGG-19 and 96.3% on InceptionV3. This is achieved using approximately one-tenth of the top encoder's inference parameters. These results demonstrate distilling semantic-segmentation features can efficiently address face-recognition pose-invariance.
翻译:本文展示了一种利用语义分隔特征改进表面识别面貌差异的新办法。 拟议的Seg- 蒸馏- ID 网络联合学习识别和语义分隔任务, 分解任务随后“ 蒸馏 ” (mobileNet 编码器) 。 业绩以公开可得的数据集上的三个最先进的编码器为基准,强调头项差别。 实验评估显示,Seg- 蒸馏- ID 网络显示出显著的稳健性效益,在ResNet- 101上实现了99.9%的测试- 准确性,在ResNet- 101上实现了81.6%,在VGG-19上实现了96.1%的测试- 准确性,在受感官V3中实现了96.3%的测试- 。 这是使用大约十分之一的顶层编码推断参数实现的。 这些结果表明, 蒸馏语义分解特性能够有效地解决表面识别的容变差。