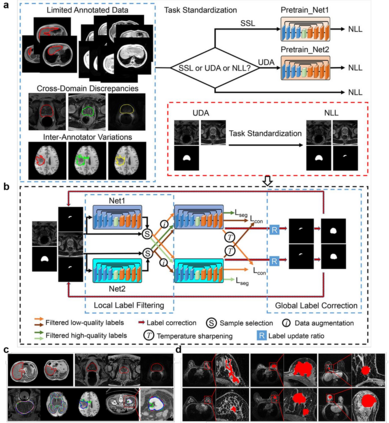
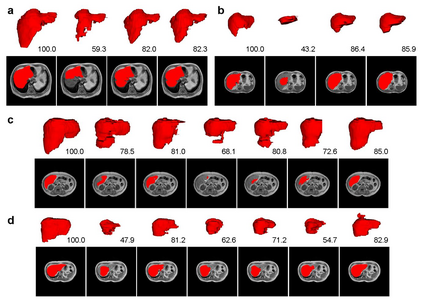
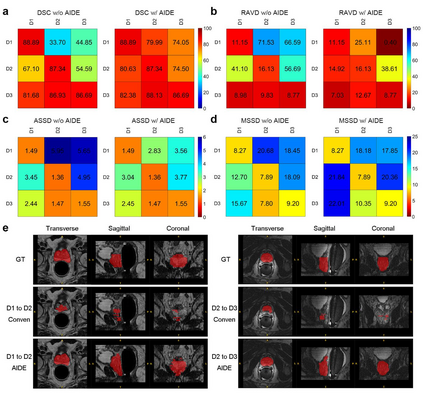
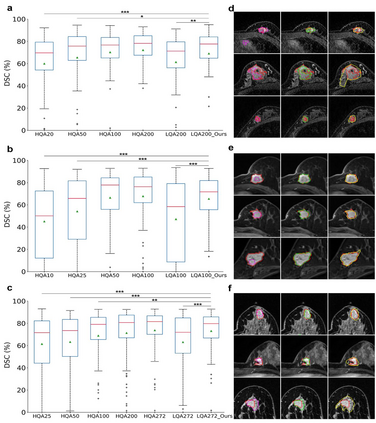
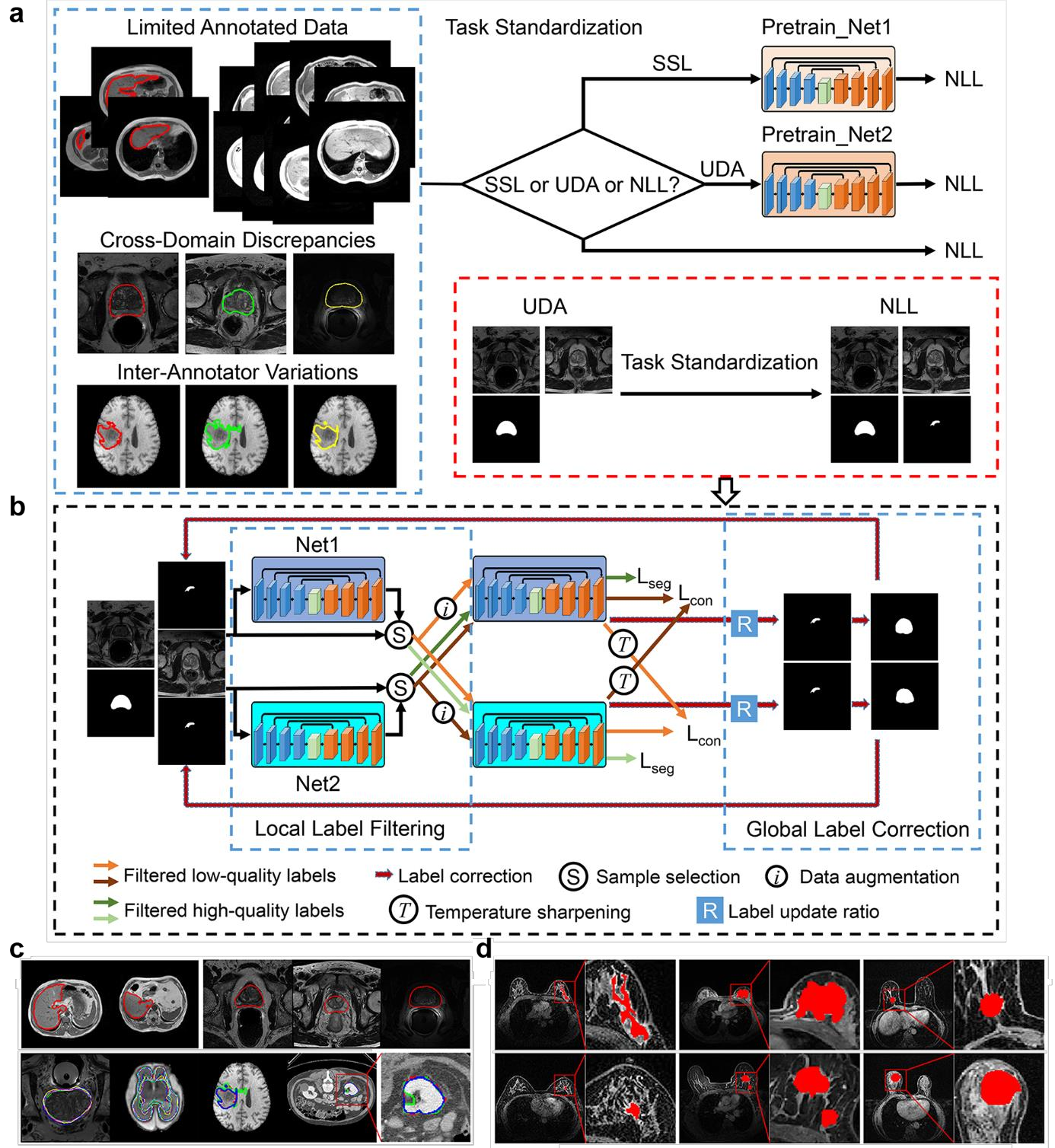
Automatic medical image segmentation plays a critical role in scientific research and medical care. Existing high-performance deep learning methods typically rely on large training datasets with high-quality manual annotations, which are difficult to obtain in many clinical applications. Here, we introduce Annotation-effIcient Deep lEarning (AIDE), an open-source framework to handle imperfect training datasets. Methodological analyses and empirical evaluations are conducted, and we demonstrate that AIDE surpasses conventional fully-supervised models by presenting better performance on open datasets possessing scarce or noisy annotations. We further test AIDE in a real-life case study for breast tumor segmentation. Three datasets containing 11,852 breast images from three medical centers are employed, and AIDE, utilizing 10% training annotations, consistently produces segmentation maps comparable to those generated by fully-supervised counterparts or provided by independent radiologists. The 10-fold enhanced efficiency in utilizing expert labels has the potential to promote a wide range of biomedical applications.
翻译:现有的高性能深层学习方法通常依赖大型培训数据集,这些数据集具有高质量的人工说明,在许多临床应用中很难获得。在这里,我们引入了一个开放源码框架,处理不完善的培训数据集,进行了方法分析和经验评估,我们证明,在拥有稀缺或吵闹说明的开放数据集上,AIDE的表现优于常规的完全监督的模式。我们在乳腺癌分离的实时案例研究中进一步测试AIDE。使用三个包含11 852个乳房图像的数据集,包括三个医疗中心的11 852个乳房图像,使用10%的培训说明,不断制作可与完全监督的对应方或独立放射学家制作的相类似的分解图。10倍提高使用专家标签的效率,有可能促进广泛的生物医学应用。