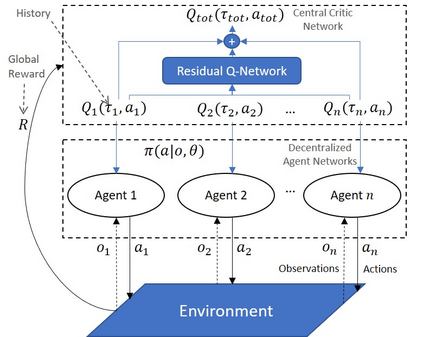
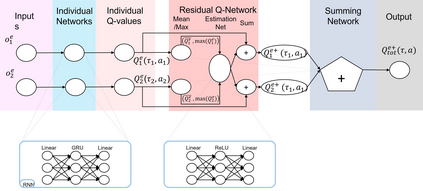
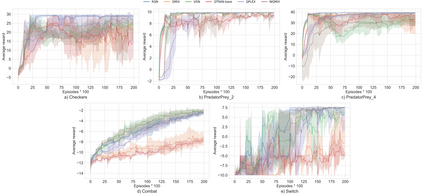
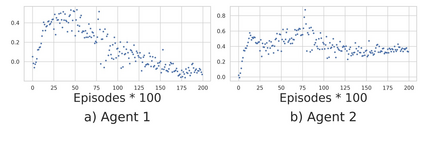
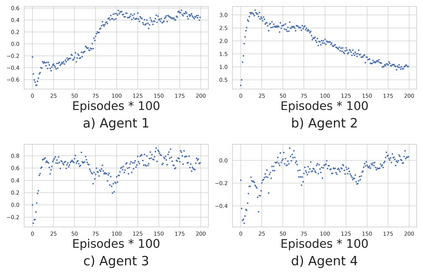
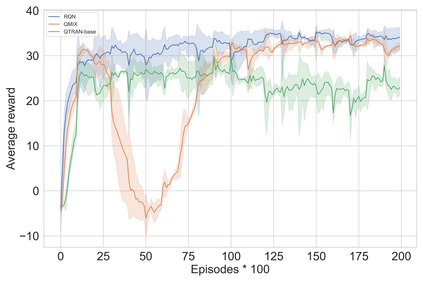
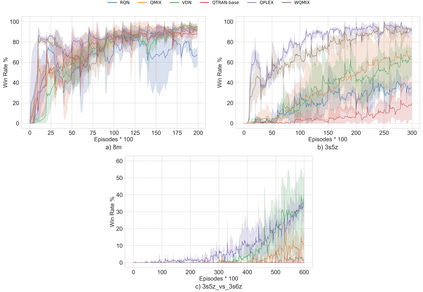
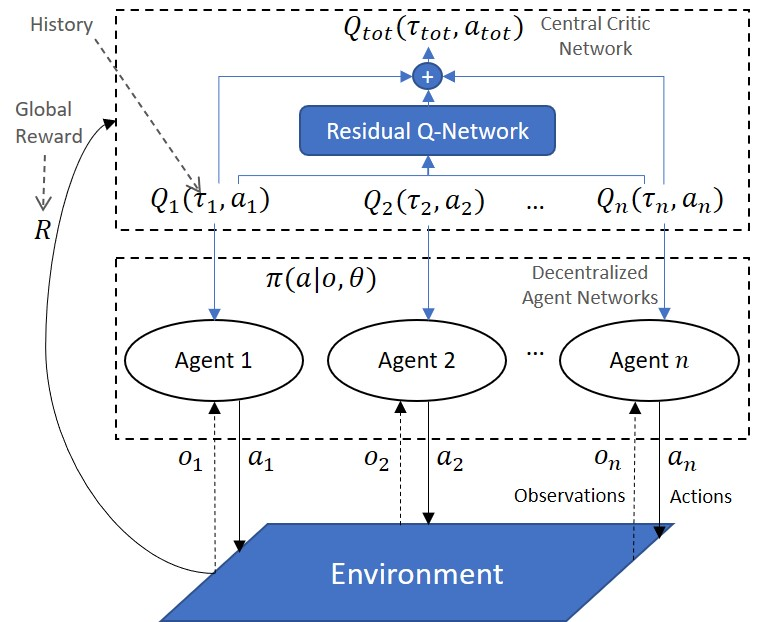
Multi-Agent Reinforcement Learning (MARL) is useful in many problems that require the cooperation and coordination of multiple agents. Learning optimal policies using reinforcement learning in a multi-agent setting can be very difficult as the number of agents increases. Recent solutions such as Value Decomposition Networks (VDN), QMIX, QTRAN and QPLEX adhere to the centralized training and decentralized execution scheme and perform factorization of the joint action-value functions. However, these methods still suffer from increased environmental complexity, and at times fail to converge in a stable manner. We propose a novel concept of Residual Q-Networks (RQNs) for MARL, which learns to transform the individual Q-value trajectories in a way that preserves the Individual-Global-Max criteria (IGM), but is more robust in factorizing action-value functions. The RQN acts as an auxiliary network that accelerates convergence and will become obsolete as the agents reach the training objectives. The performance of the proposed method is compared against several state-of-the-art techniques such as QPLEX, QMIX, QTRAN and VDN, in a range of multi-agent cooperative tasks. The results illustrate that the proposed method, in general, converges faster, with increased stability and shows robust performance in a wider family of environments. The improvements in results are more prominent in environments with severe punishments for non-cooperative behaviours and especially in the absence of complete state information during training time.
翻译:多机构强化学习(MARL)在很多需要多个代理机构合作和协调的问题中非常有用。在多个代理机构增加的情况下,学习使用强化学习的优化政策可能会随着代理机构数量的增加而非常困难。最近的解决办法,如价值分解网络(VDN)、QMIX、QTRAN和QPLEX, 坚持集中培训和分散执行计划,并履行联合行动价值功能的因子化。然而,这些方法仍然因环境复杂性增加而受到影响,有时无法以稳定的方式汇合。我们为MARL提出了一个新颖的残余QNetwork(RQNs)技术概念,它学会以维护个人-全球质量标准(IMM)、QMIX、QPL(QQN)标准的方式改变个人价值轨迹,但更有力地将行动价值功能因素化。RQN作为辅助网络,加速趋同,随着代理机构达到培训目标而过时。与QPLEXQQNNNQM(QQQQQIX)的显著的不透明性环境中,在合作性培训过程中,越快的成绩越快,越快地展示了拟议方法的成绩。