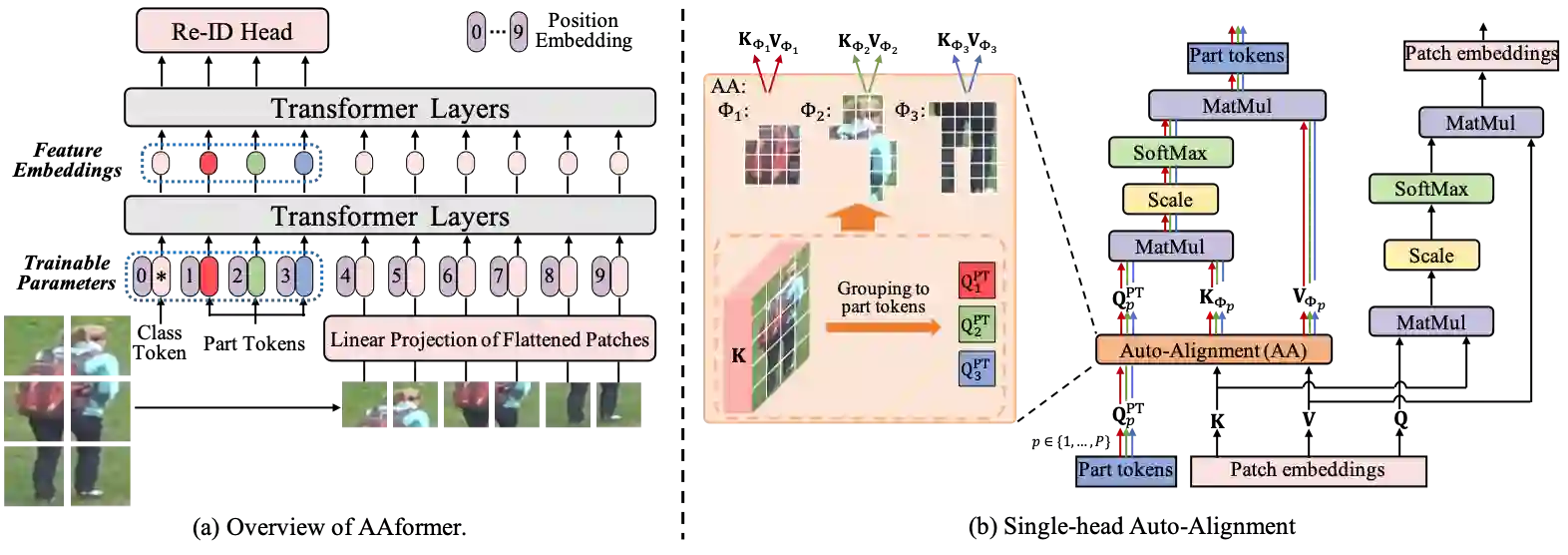
In person re-identification, extracting part-level features from person images has been verified to be crucial. Most of existing CNN-based methods only locate the human parts coarsely, or rely on pre-trained human parsing models and fail in locating the identifiable non-human parts (e.g., knapsack). In this paper, we introduce an alignment scheme in Transformer architecture for the first time and propose the Auto-Aligned Transformer (AAformer) to automatically locate both the human parts and non-human ones at patch-level. We introduce the "part tokens", which are learnable vectors, to extract part features in Transformer. A part token only interacts with a local subset of patches in self-attention and learns to be the part representation. To adaptively group the image patches into different subsets, we design the Auto-Alignment. Auto-Alignment employs a fast variant of Optimal Transport algorithm to online cluster the patch embeddings into several groups with the part tokens as their prototypes. We harmoniously integrate the part alignment into the self-attention and the output part tokens can be directly used for retrieval. Extensive experiments validate the effectiveness of part tokens and the superiority of AAformer over various state-of-the-art methods.
翻译:个人重新识别, 从个人图像中提取部分级别特性已被验证为关键。 大部分现有的CNN 方法仅粗略地定位人体部分, 或依赖经过预先训练的人类剖析模型, 并且未能定位可识别的非人类部分( 例如 knapsack ) 。 在本文中, 我们首次在变异器结构中引入一个校准方案, 并提议自动自动变异器( AAAAAAEx) 自动将人体部分和非人类部分都定位在补丁级别。 我们引入了“ 部分标志 ”, 它们是可学习的矢量, 以提取变异器中的部分特性。 部分象征只与局部的自我注意部分互动, 并学习如何定位可识别的非人类部分( 如 knapsack ) 。 为了适应性地将图像补装到不同的子组中, 我们设计了自动适配方运算法的快速变式, 将部分嵌入到几个组中作为原型符号。 我们将部分与部分的可学习的矢量矢量矢中, 。 我们将部分与部分整合到自我保存部分的自留和输出部分的磁度测试部分。 将直接用于对等的质质质质质的质测试。 。