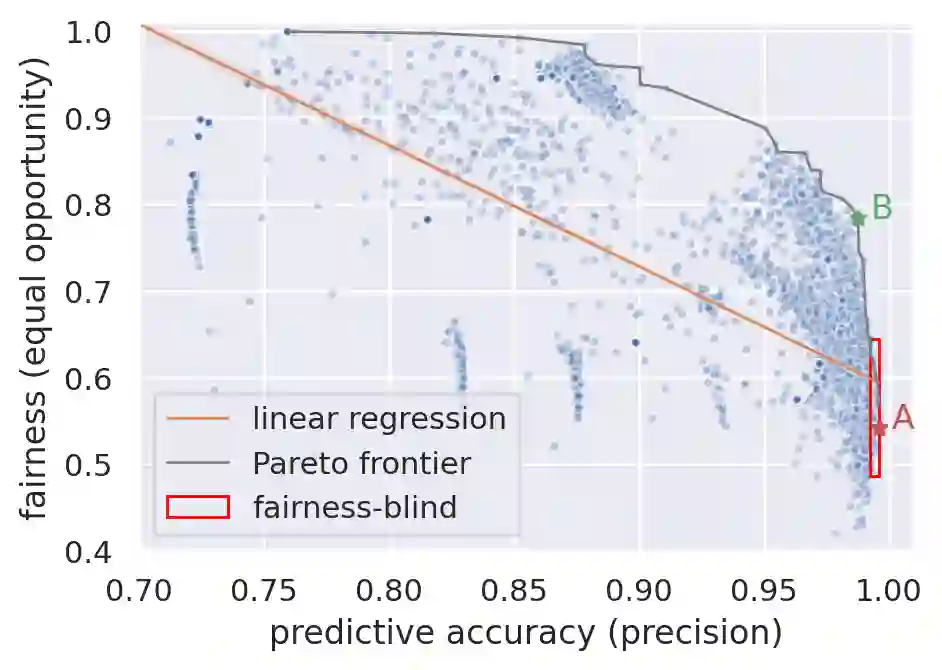
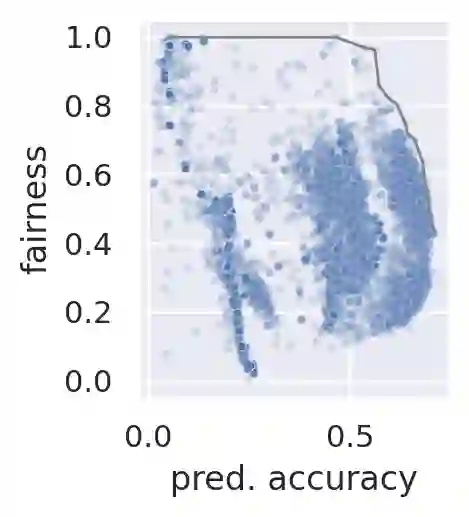
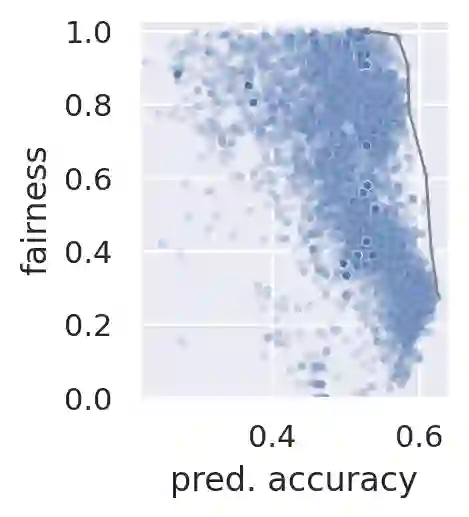
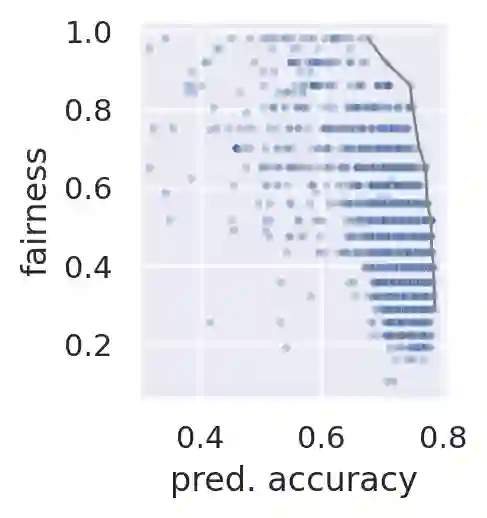
Considerable research effort has been guided towards algorithmic fairness but real-world adoption of bias reduction techniques is still scarce. Existing methods are either metric- or model-specific, require access to sensitive attributes at inference time, or carry high development and deployment costs. This work explores, in the context of a real-world fraud detection application, the unfairness that emerges from traditional ML model development, and how to mitigate it with a simple and easily deployed intervention: fairness-aware hyperparameter optimization (HO). We propose and evaluate fairness-aware variants of three popular HO algorithms: Fair Random Search, Fair TPE, and Fairband. Our method enables practitioners to adapt pre-existing business operations to accommodate fairness objectives in a frictionless way and with controllable fairness-accuracy trade-offs. Additionally, it can be coupled with existing bias reduction techniques to tune their hyperparameters. We validate our approach on a real-world bank account opening fraud use case, as well as on three datasets from the fairness literature. Results show that, without extra training cost, it is feasible to find models with 111% average fairness increase and just 6% decrease in predictive accuracy, when compared to standard fairness-blind HO.
翻译:已经引导了相当的研究工作,以实现算法公平,但现实世界仍然很少采用减少偏见的技术。现有的方法要么是衡量或模型特定的方法,要求在推论时间获得敏感属性,要么是高的开发和部署成本。这项工作在现实世界欺诈检测应用中探索了传统ML模型开发过程中出现的不公平,以及如何通过简单和容易采用的干预来减轻这种不公平:公平了解超分法优化。我们提议和评价三种受欢迎的HO算法的公平认识变式:公平随机搜索、公平TEP和公平带。我们的方法使从业人员能够以没有摩擦和可控制的公平准确交易的方式调整现有的商业业务,以适应公平目标。此外,还可以结合现有的减少偏差技术来调整其超分数。我们验证了我们在真实世界银行账户开设欺诈案件以及公平文献的三个数据集上的做法。结果显示,在没有额外培训成本的情况下,可以找到平均公平性提高111%的模型,在预测准确度方面降低6 % 。相比之下,在预测准确性时,可以找到平均公平性提高101%的模型,在预测性方面降低6 % 。