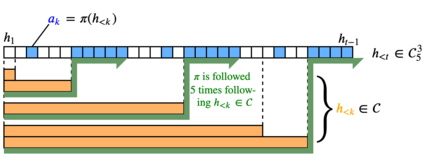
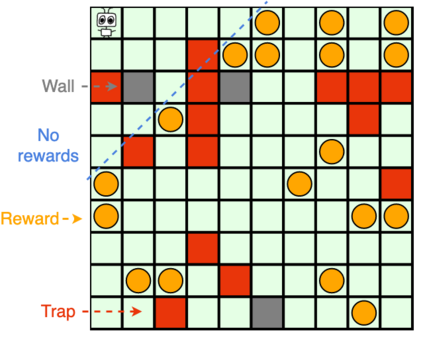
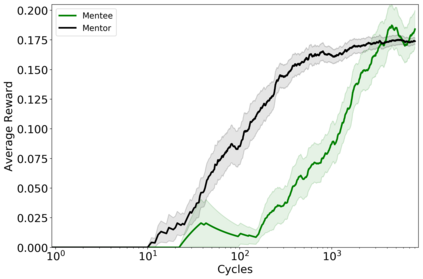
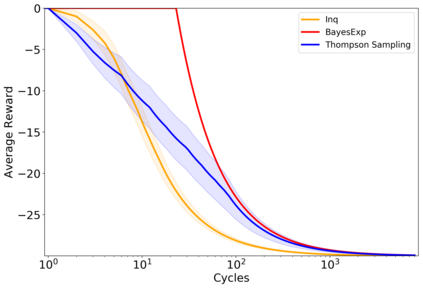
Reinforcement learners are agents that learn to pick actions that lead to high reward. Ideally, the value of a reinforcement learner's policy approaches optimality--where the optimal informed policy is the one which maximizes reward. Unfortunately, we show that if an agent is guaranteed to be "asymptotically optimal" in any (stochastically computable) environment, then subject to an assumption about the true environment, this agent will be either "destroyed" or "incapacitated" with probability 1. Much work in reinforcement learning uses an ergodicity assumption to avoid this problem. Often, doing theoretical research under simplifying assumptions prepares us to provide practical solutions even in the absence of those assumptions, but the ergodicity assumption in reinforcement learning may have led us entirely astray in preparing safe and effective exploration strategies for agents in dangerous environments. Rather than assuming away the problem, we present an agent, Mentee, with the modest guarantee of approaching the performance of a mentor, doing safe exploration instead of reckless exploration. Critically, Mentee's exploration probability depends on the expected information gain from exploring. In a simple non-ergodic environment with a weak mentor, we find Mentee outperforms existing asymptotically optimal agents and its mentor.
翻译:强化学习者是学会选择导致高报酬的行动的代理人。 理想的情况是,强化学习者政策方法的价值是最佳的。 理想的情况是,强化学习者的政策方法的价值是最佳的—— 最佳的知情政策是最佳的奖励。 不幸的是,我们表明,如果一个代理人保证在任何(随机可比较的)环境中“暂时最佳 ”, 那么在假设真实环境的前提下,该代理人要么“被破坏”,要么“丧失能力 ” 。 强化学习工作的大部分工作利用一个荒谬的假设来避免这一问题。 通常,在简化假设下进行理论研究,使我们提供切实可行的解决办法,即使没有这些假设,但强化学习中的错误假设可能使我们在为危险环境中的代理人制定安全有效的勘探战略方面完全误差。 我们提出一个代理人,Mentee,在接近导师的绩效时,进行安全的探索而不是鲁莽的探索。 关键地说,Mentee的探索概率取决于从探索中获得的预期信息。 在简单的非最佳导师制中,我们发现一个软弱的导师环境。