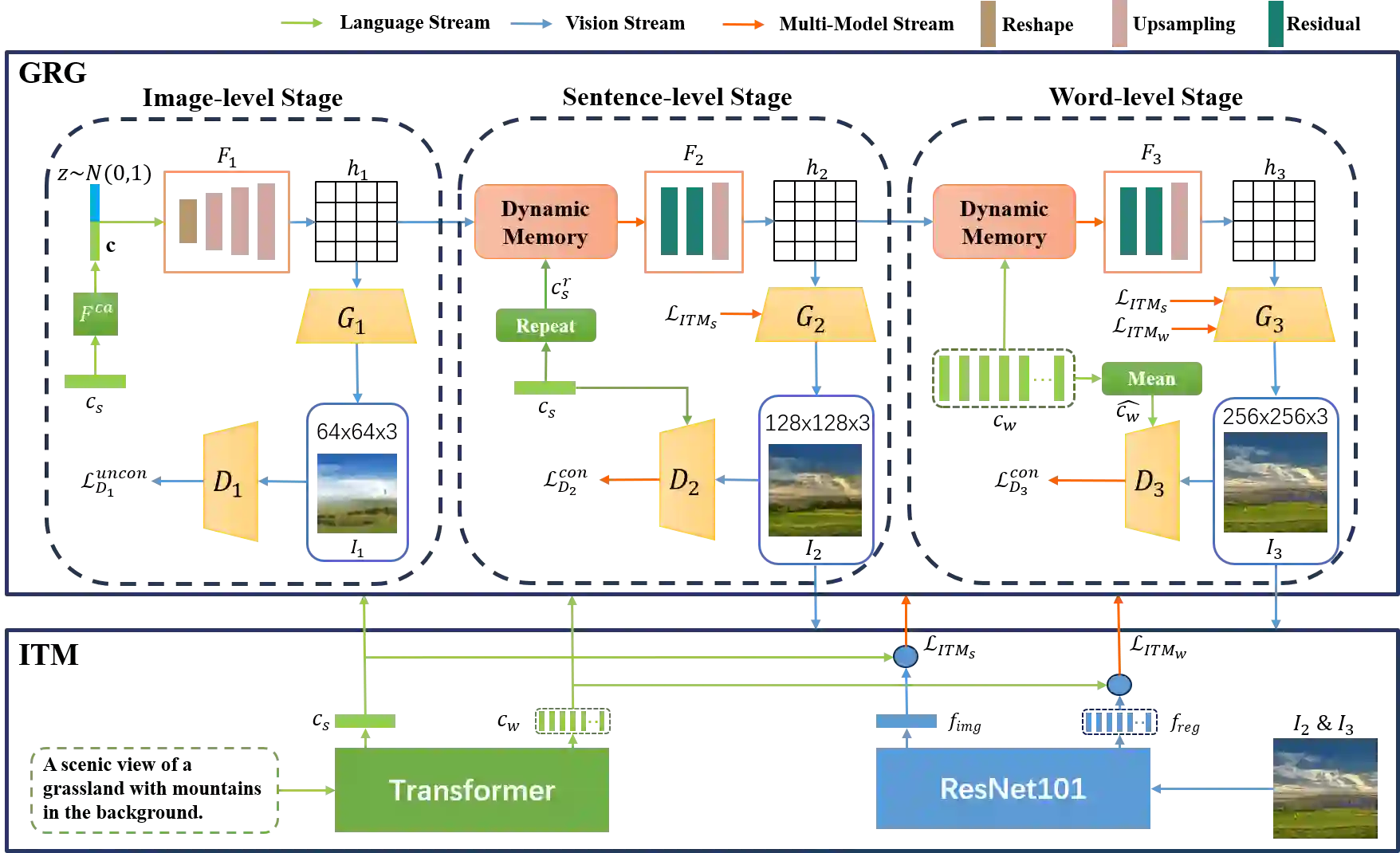
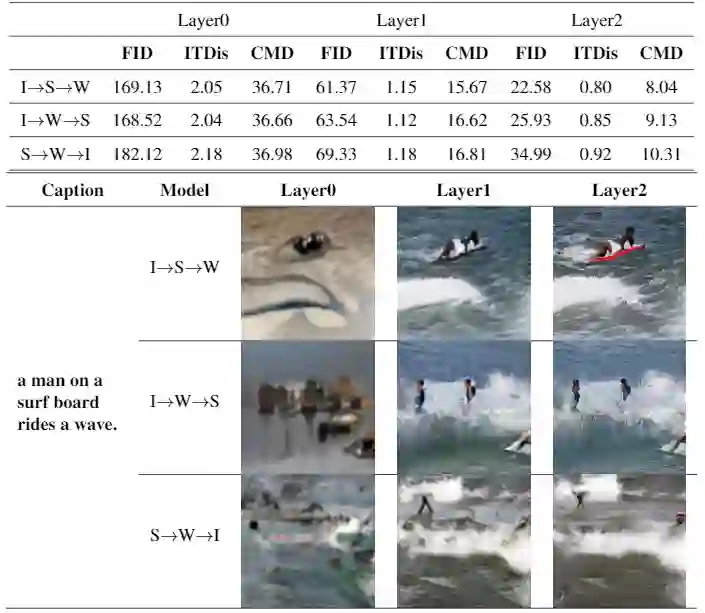
A good Text-to-Image model should not only generate high quality images, but also ensure the consistency between the text and the generated image. Previous models failed to simultaneously fix both sides well. This paper proposes a Gradual Refinement Generative Adversarial Network (GR-GAN) to alleviates the problem efficiently. A GRG module is designed to generate images from low resolution to high resolution with the corresponding text constraints from coarse granularity (sentence) to fine granularity (word) stage by stage, a ITM module is designed to provide image-text matching losses at both sentence-image level and word-region level for corresponding stages. We also introduce a new metric Cross-Model Distance (CMD) for simultaneously evaluating image quality and image-text consistency. Experimental results show GR-GAN significant outperform previous models, and achieve new state-of-the-art on both FID and CMD. A detailed analysis demonstrates the efficiency of different generation stages in GR-GAN.
翻译:良好的文本到图像模型不仅应产生高质量的图像,而且还应确保文本与生成图像的一致性。 以前的模型未能同时同时修正两侧。 本文建议建立一个渐进式精化生成反图像网络( GR- GAN) 以有效缓解问题。 一个 GRG 模块旨在生成低分辨率到高分辨率的图像, 其相应的文本限制来自粗微颗粒( 恒定) 和微微颗粒( 字词) 阶段, 一个 ITM 模块旨在为相应阶段的句模级和字区级提供图像文本匹配损失。 我们还引入了一个新的衡量图像质量和图像文本一致性的跨模数距离( CMD ) 。 实验结果显示GR- GAN 显著地超越了以前的模型, 并实现了关于FID和 CMD的新的状态。 详细分析显示G- GAN 不同生成阶段的效率。