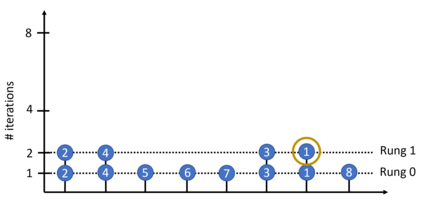
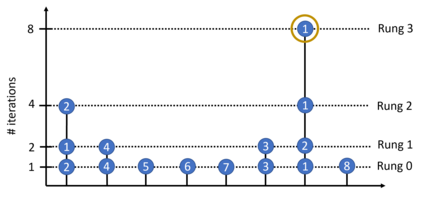
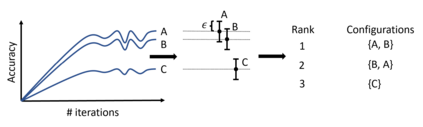
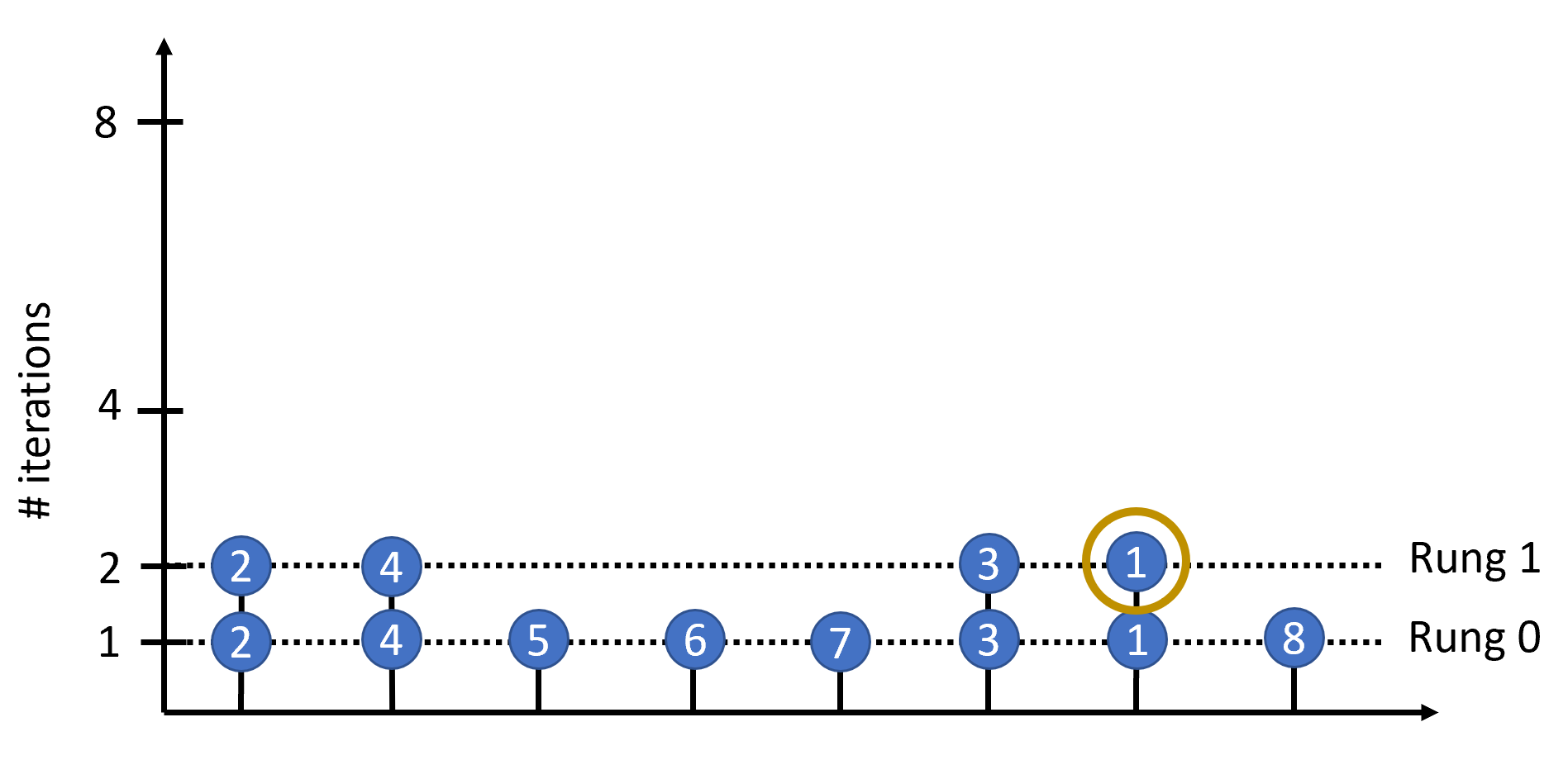
Hyperparameter optimization (HPO) and neural architecture search (NAS) are methods of choice to obtain the best-in-class machine learning models, but in practice they can be costly to run. When models are trained on large datasets, tuning them with HPO or NAS rapidly becomes prohibitively expensive for practitioners, even when efficient multi-fidelity methods are employed. We propose an approach to tackle the challenge of tuning machine learning models trained on large datasets with limited computational resources. Our approach, named PASHA, is able to dynamically allocate maximum resources for the tuning procedure depending on the need. The experimental comparison shows that PASHA identifies well-performing hyperparameter configurations and architectures while consuming significantly fewer computational resources than solutions like ASHA.
翻译:超光计优化(HPO)和神经结构搜索(NAS)是获得最优级机床学习模型的首选方法,但实际上它们运行成本可能很高。当模型在大型数据集上接受培训时,使用HPO或NAS对模型进行调试,对实践者来说成本非常高,即使采用了高效的多信仰方法。我们建议了一种方法来应对在计算资源有限的大数据集上培训的机床学习模型的调试的挑战。我们的方法叫做PASHA,它能够根据需要动态地为调控程序分配最大资源。实验性比较表明PASHA发现运行良好的超参数配置和结构,同时消耗的计算资源远远少于ASHA这样的计算资源。