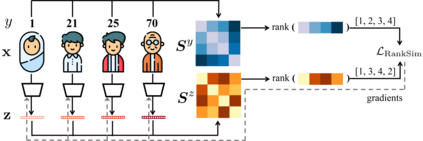
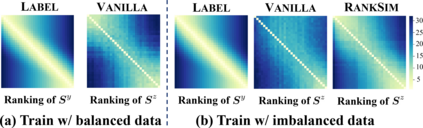
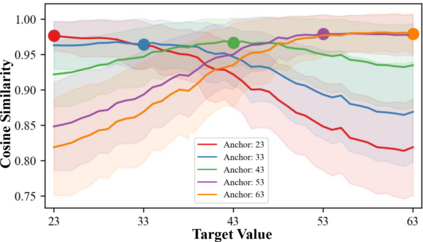
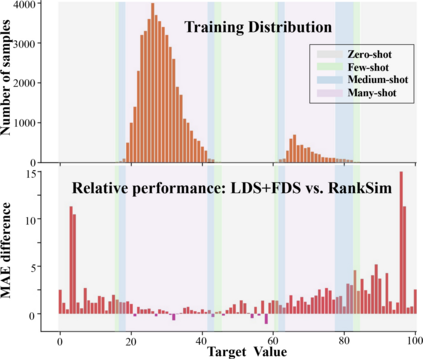
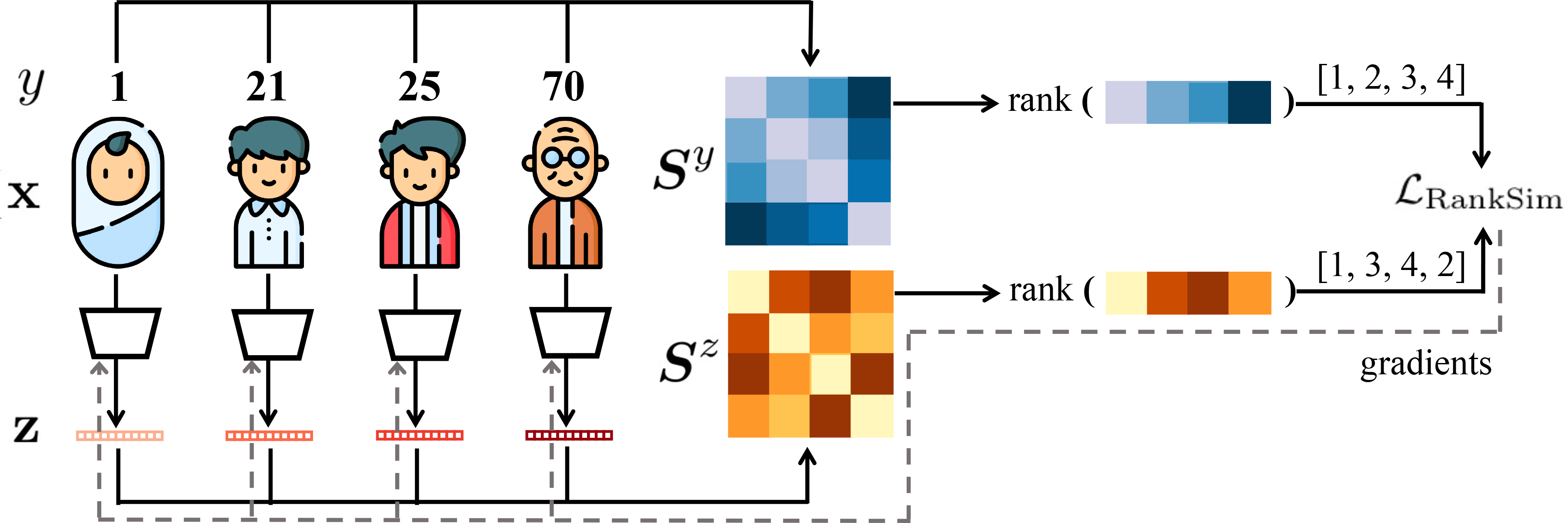
Data imbalance, in which a plurality of the data samples come from a small proportion of labels, poses a challenge in training deep neural networks. Unlike classification, in regression the labels are continuous, potentially boundless, and form a natural ordering. These distinct features of regression call for new techniques that leverage the additional information encoded in label-space relationships. This paper presents the RankSim (ranking similarity) regularizer for deep imbalanced regression, which encodes an inductive bias that samples that are closer in label space should also be closer in feature space. In contrast to recent distribution smoothing based approaches, RankSim captures both nearby and distant relationships: for a given data sample, RankSim encourages the sorted list of its neighbors in label space to match the sorted list of its neighbors in feature space. RankSim is complementary to conventional imbalanced learning techniques, including re-weighting, two-stage training, and distribution smoothing, and lifts the state-of-the-art performance on three imbalanced regression benchmarks: IMDB-WIKI-DIR, AgeDB-DIR, and STS-B-DIR.
翻译:数据不平衡,其中多种数据样本来自一小部分标签,在培训深神经网络方面构成挑战。与分类不同,回归标签是连续的、潜在的无限的,并形成自然的顺序。回归的这些特点要求采用新的技术,利用标签-空间关系中编码的额外信息。本文介绍了关于深度不平衡回归的RankSim(排序相似性)常规化标准,该标准编码了一个暗示偏差,即标签空间更接近的样本也应该在特征空间中更加接近。与最近基于分布的平滑方法相比,RankSim捕捉了附近和远处的关系:对于特定的数据样本,RankSim鼓励其标签空间邻居的分类名单与其在特征空间中的邻居的分类清单相匹配。RankSim是对传统的不平衡学习技术的补充,包括重新加权、两阶段培训、分布平滑,以及提高三个不平衡回归基准(IMDB-WIKI-DIR、ADB-DIR和STSS-B-DIR)的状态性表现。