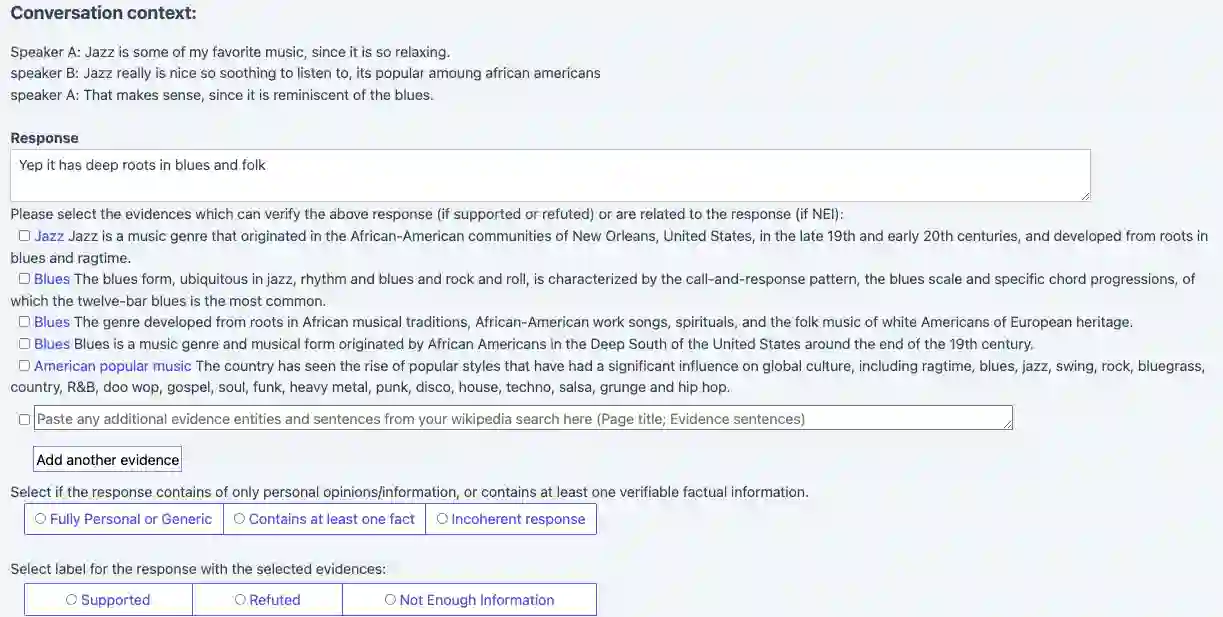
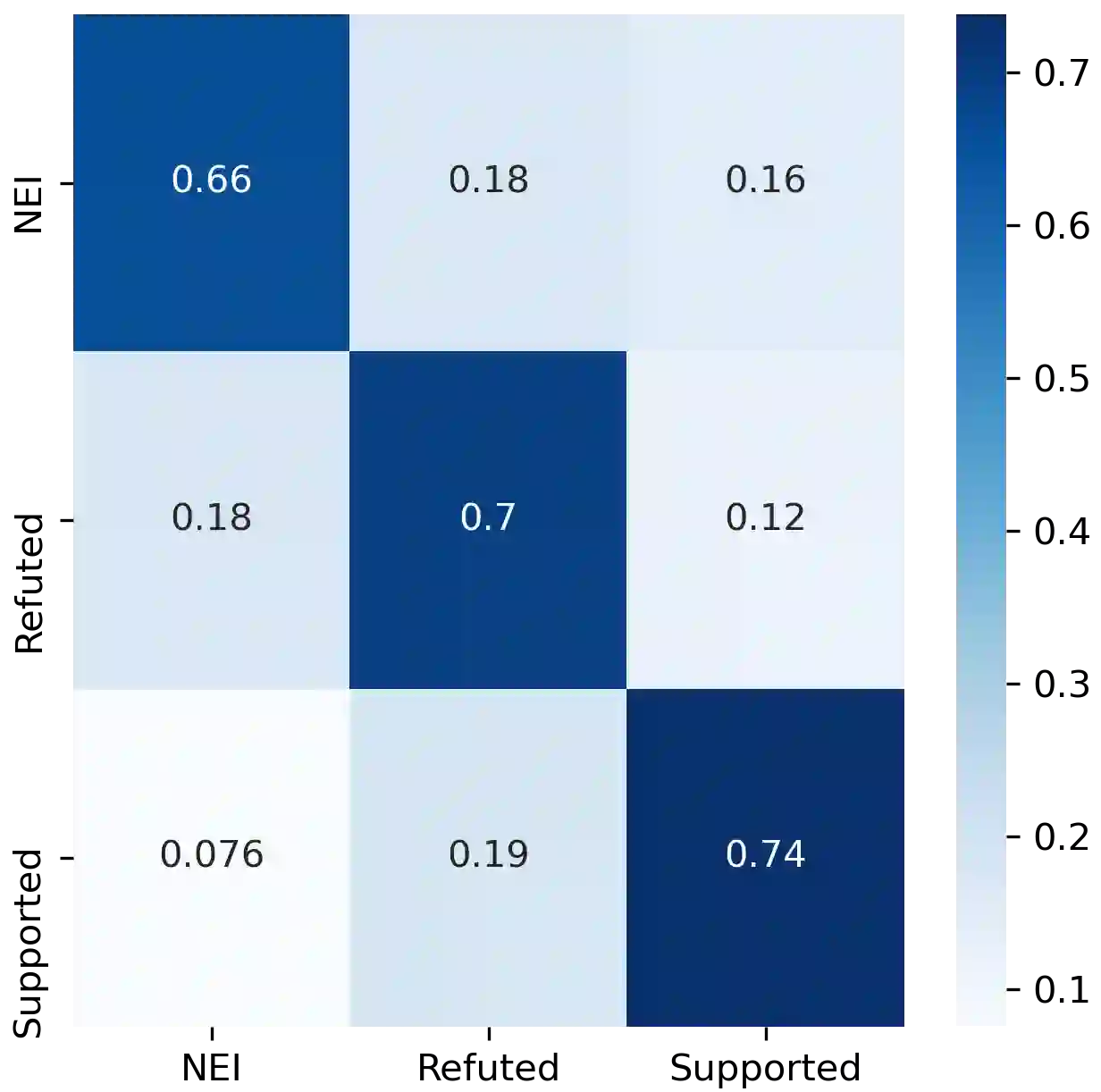
Fact-checking is an essential tool to mitigate the spread of misinformation and disinformation, however, it has been often explored to verify formal single-sentence claims instead of casual conversational claims. To study the problem, we introduce the task of fact-checking in dialogue. We construct DialFact, a testing benchmark dataset of 22,245 annotated conversational claims, paired with pieces of evidence from Wikipedia. There are three sub-tasks in DialFact: 1) Verifiable claim detection task distinguishes whether a response carries verifiable factual information; 2) Evidence retrieval task retrieves the most relevant Wikipedia snippets as evidence; 3) Claim verification task predicts a dialogue response to be supported, refuted, or not enough information. We found that existing fact-checking models trained on non-dialogue data like FEVER fail to perform well on our task, and thus, we propose a simple yet data-efficient solution to effectively improve fact-checking performance in dialogue. We point out unique challenges in DialFact such as handling the colloquialisms, coreferences, and retrieval ambiguities in the error analysis to shed light on future research in this direction.
翻译:事实检查是减少错误和虚假信息扩散的基本工具,然而,经常探讨如何用事实检查来核实正式的单一判决要求,而不是泛泛的谈话要求。为了研究这一问题,我们提出在对话中进行事实检查的任务。我们建立了DialFact,这是22 245个附加说明的谈话要求的测试基准数据集,与维基百科提供的证据相配。在DialFact中有三个次级任务:1)可核实的索赔检验任务区分一项答复是否包含可核查的事实信息;2)证据检索任务检索最相关的维基百科片作为证据;3)索赔核查任务预测对话反应将得到支持、反驳或不充分的信息。我们发现,现有关于Fever等非对话数据培训的事实核查模型未能很好地完成我们的任务,因此我们提出了一个简单但有效的解决方案,以有效改进对话中的事实检查业绩。我们指出, DialFact在处理学术辩论、参照和检索错误分析中的模糊性以说明未来研究方向。