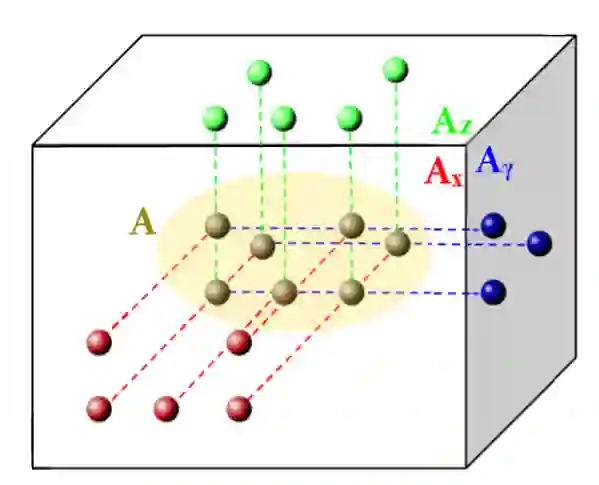
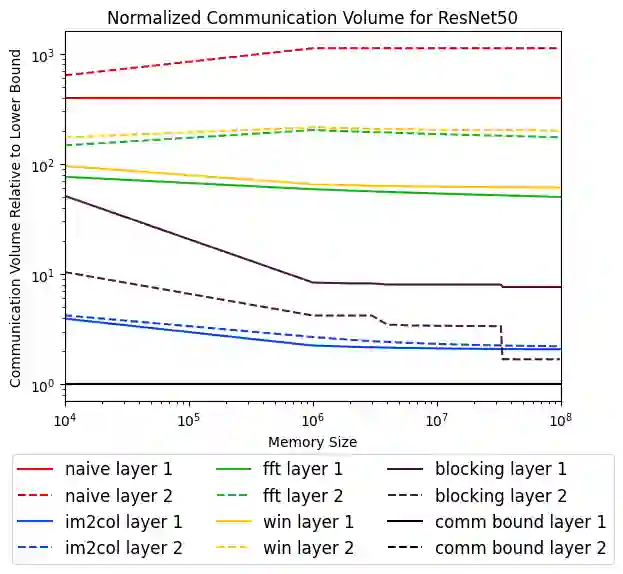
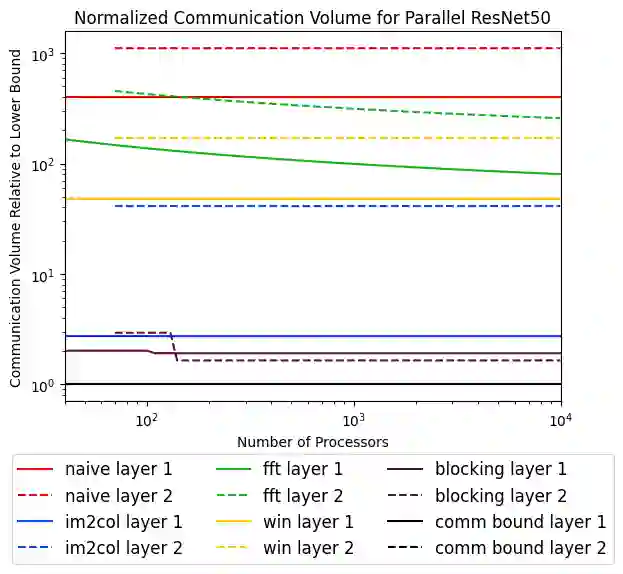
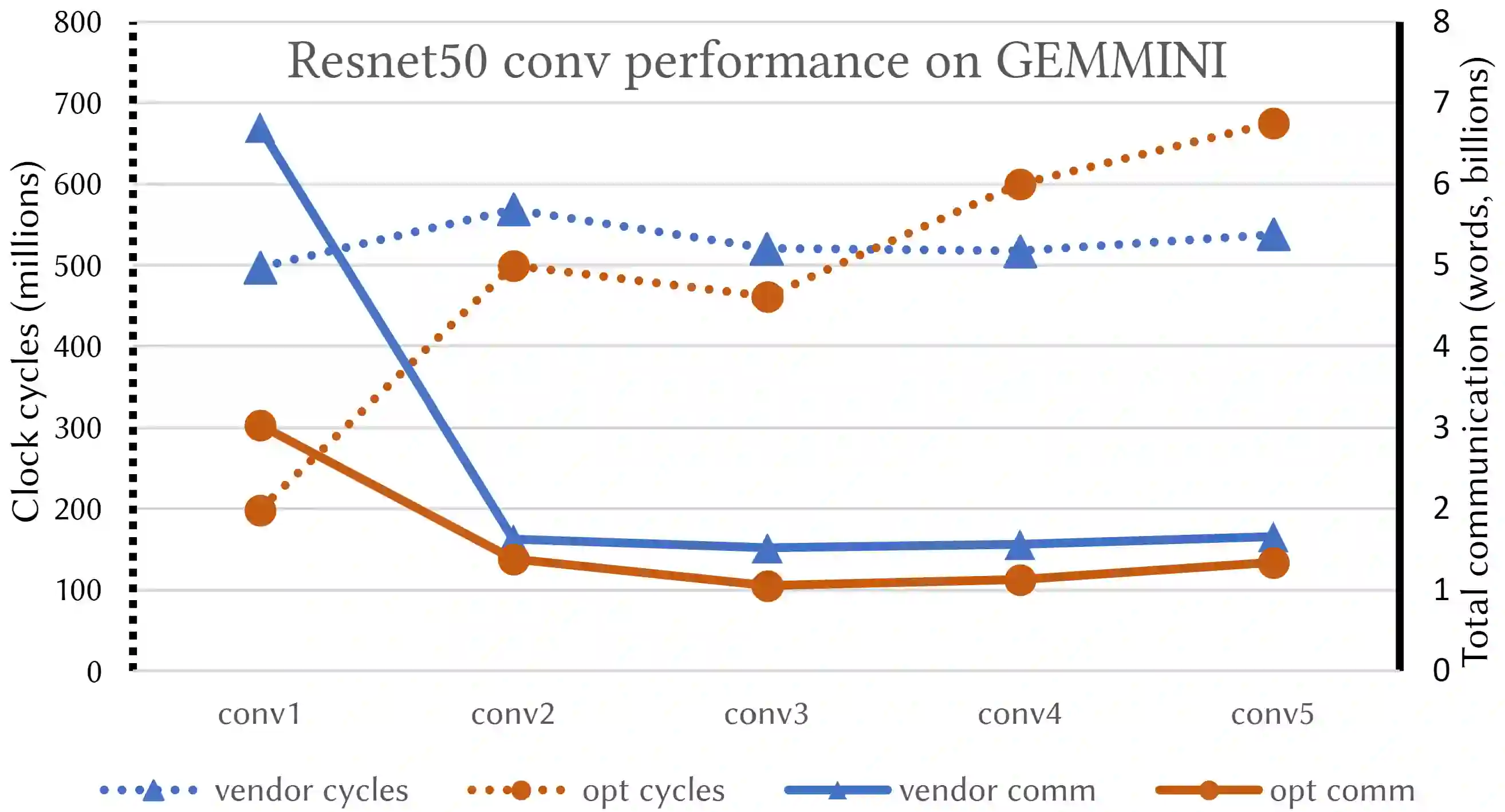
Convolutional neural networks (CNNs) are important in a wide variety of machine learning tasks and applications, so optimizing their performance is essential. Moving words of data between levels of a memory hierarchy or between processors on a network is much more expensive than the cost of arithmetic, so minimizing communication is critical to optimizing performance. In this paper, we present new lower bounds on data movement for mixed precision convolutions in both single-processor and parallel distributed memory models, as well as algorithms that outperform current implementations such as Im2Col. We obtain performance figures using GEMMINI, a machine learning accelerator, where our tiling provides improvements between 13% and 150% over a vendor supplied algorithm.
翻译:革命性神经网络(CNNs)在各种机器学习任务和应用中都很重要,因此,优化其性能是必不可少的。在记忆层层次之间或网络处理器之间移动数据词汇比算术成本昂贵得多,因此最大限度地减少通信对于优化性能至关重要。在本文中,我们提出了在单一处理器和平行分布式存储模型中混合精度变化数据流动的新下限,以及比当前实施方式(如IM2Col)超速的算法。我们用机器学习加速器GEMMINI(机器学习加速器)获得性能数字,我们的平铺比供应商提供的算法改进了13%至150%。