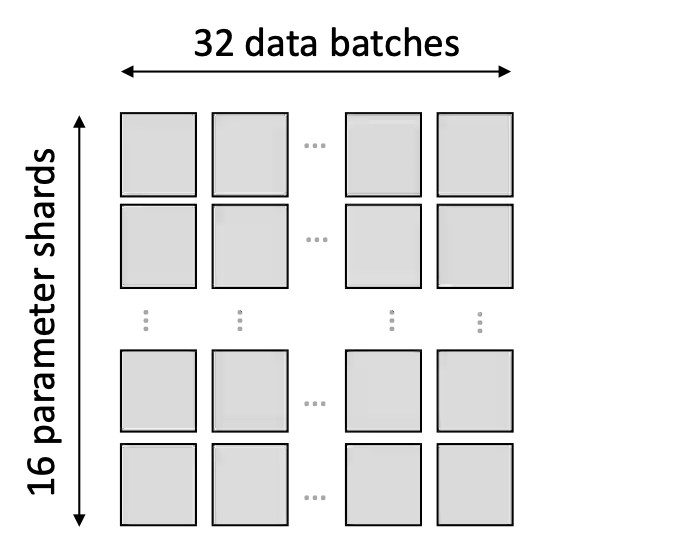
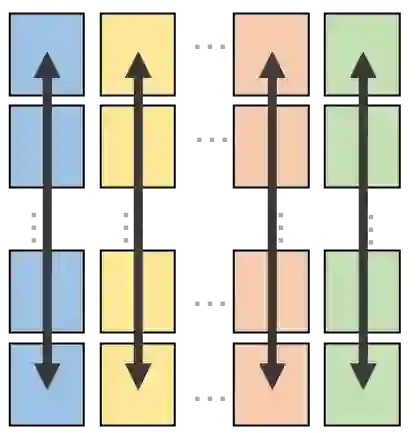
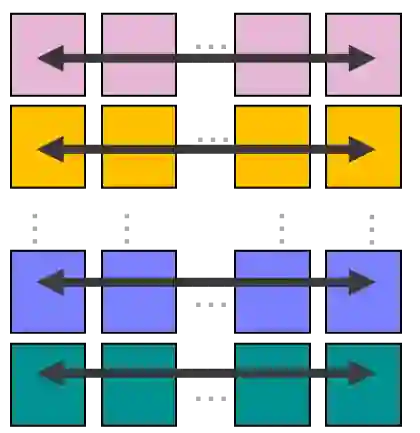
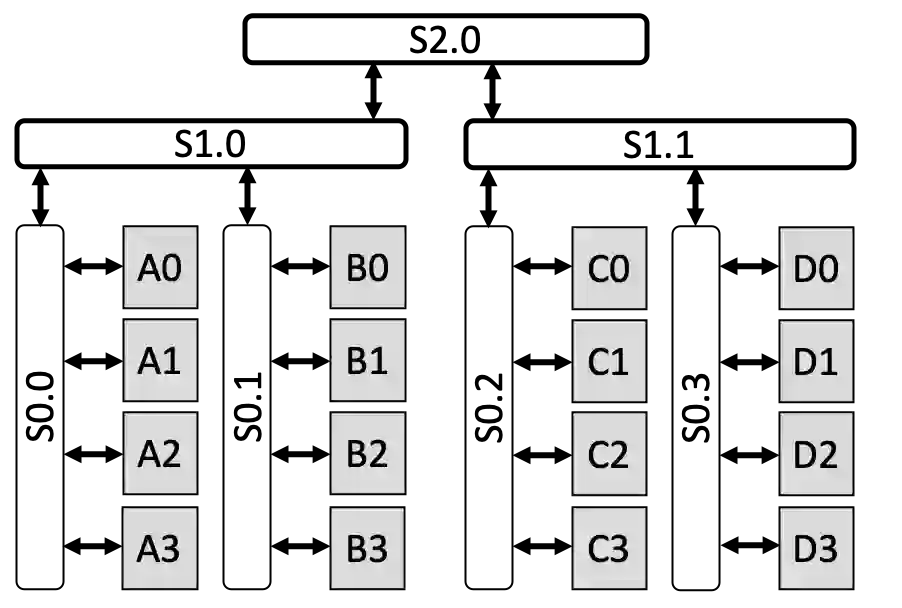
We present a novel characterization of the mapping of multiple parallelism forms (e.g. data and model parallelism) onto hierarchical accelerator systems that is hierarchy-aware and greatly reduces the space of software-to-hardware mapping. We experimentally verify the substantial effect of these mappings on all-reduce performance (up to 448x). We offer a novel syntax-guided program synthesis framework that is able to decompose reductions over one or more parallelism axes to sequences of collectives in a hierarchy- and mapping-aware way. For 69% of parallelism placements and user requested reductions, our framework synthesizes programs that outperform the default all-reduce implementation when evaluated on different GPU hierarchies (max 2.04x, average 1.27x). We complement our synthesis tool with a simulator exceeding 90% top-10 accuracy, which therefore reduces the need for massive evaluations of synthesis results to determine a small set of optimal programs and mappings.
翻译:我们展示了一种新颖的特征,将多重平行形式(如数据和模型平行)的绘图描述为等级级加速器系统,这种系统具有等级意识,大大缩小了软件到硬件的绘图空间。我们实验性地核实了这些绘图对全减性能(最高为448x)产生的实质性影响。我们提供了一个新的语法指导程序合成框架,能够将一个或一个以上平行轴的削减分解成一个等级级和绘图认知方式的集体序列。对于69%的平行安置和用户要求的削减,我们的框架综合了在对不同的GPU结构进行评估时超过默认的全减量执行程序(平均为2.04x,平均为1.27x)。我们用一个超过90%的十强精度的模拟器来补充我们的合成工具,因此减少了大规模合成结果评估的必要性,以确定一套小型的最佳方案和绘图。