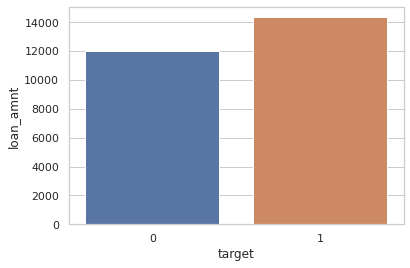
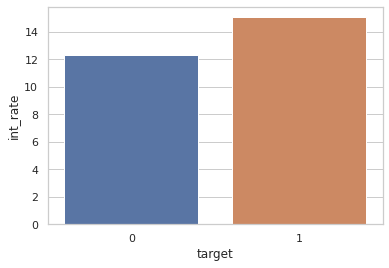
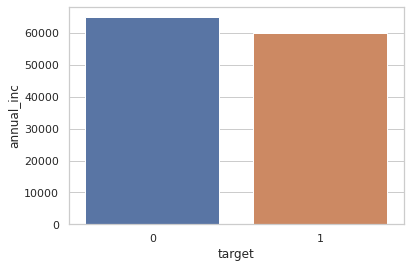
Bootstrap aggregation, known as bagging, is one of the most popular ensemble methods used in machine learning (ML). An ensemble method is a ML method that combines multiple hypotheses to form a single hypothesis used for prediction. A bagging algorithm combines multiple classifiers modeled on different sub-samples of the same data set to build one large classifier. Banks, and their retail banking activities, are nowadays using the power of ML algorithms, including decision trees and random forests, to optimize their processes. However, banks have to comply with regulators and governance and, hence, delivering effective ML solutions is a challenging task. It starts with the bank's validation and governance department, followed by the deployment of the solution in a production environment up to the external validation of the national financial regulator. Each proposed ML model has to be validated and clear rules for every algorithm-based decision must be justified. In this context, we propose XtracTree, an algorithm capable of efficiently converting an ML bagging classifier, such as a random forest, into simple "if-then" rules satisfying the requirements of model validation. We use a public loan data set from Kaggle to illustrate the usefulness of our approach. Our experiments demonstrate that using XtracTree, one can convert an ML model into a rule-based algorithm, leading to easier model validation by national financial regulators and the bank's validation department. The proposed approach allowed our banking institution to reduce up to 50% the time of delivery of our AI solutions to the end-user.
翻译:套用算法结合了以同一数据集的不同子样本为模型的多个分类器,以构建一个大型分类器。银行及其零售银行活动现在使用ML算法的力量,包括决策树和随机森林来优化其流程。然而,银行必须遵守监管者和治理者,因此,提供有效的 ML 解决方案是一项艰巨的任务。从银行的验证和治理部门开始,然后在生产环境中部署解决方案,直到国家金融监管机构的外部验证。每一个拟议的 ML 模型都必须经过验证,每个基于算法的决定都必须有明确的规则。在这方面,我们提出Xtrac 模型,一种允许的算法,能够有效地将ML baging 分类器(例如随机的森林)转换成简单的“if-then”交付规则。我们用一个“XL ” 模型来验证我们的银行系统。我们用一个测试模型来展示我们的公共数据集,用一个工具来演示我们的银行的验证规则。