LibRec 每周算法:Wide & Deep (by Google)
本周要介绍Google发表于DLRS 2016的一篇文章:Wide & Deep Learning for Recommender Systems, 该模型将宽度模型与深度网络进行联合训练, 结合了记忆与归纳的能力,有效地增加了Google play的软件安装量。
Heng-Tze Cheng, Levent Koc, Jeremiah Harmsen, Tal Shaked, Tushar Chandra, Hrishi Aradhye, Glen Anderson, Greg Corrado, Wei Chai, Mustafa Ispir, Rohan Anil, Zakaria Haque, Lichan Hong, Vihan Jain, Xiaobing Liu, Hemal Shah, Google Inc, Wide & Deep Learning for Recommender Systems, DLRS 2016
Wide & Deep Learning适于大规模的带有稀疏输入的回归与分类问题。比如推荐系统,搜索,排名等。 同时,本文对Google Play的推荐系统有较完整的描述, 是一篇实践性与落地性较强的文章。
本文贡献:
提出The Wide&Deep learning framework
The Wide&Deep learning framework 在Google play中成功应用
该框架已开源(https://research.googleblog.com/2016/06/wide-deep-learning-better-together-with.html)
推荐系统整体架构
推荐系统主要由Retrieval System与Ranking system两部分组成。输入query,是用户信息与上下文信息构成的特征,输出则是经过推荐模型排序的条目列表。
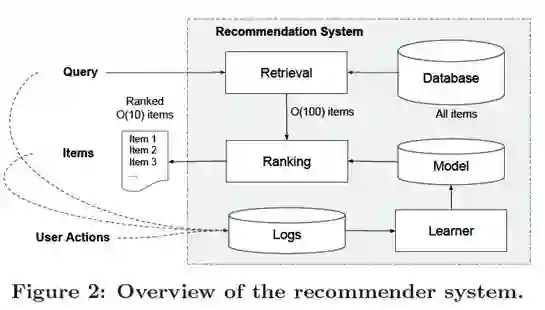
本文重点为Ranking System:Wide & Deep learning framework.
WIDE & DEEP LEARNING
本文是将Wide Models(Figure1,最左侧) 与 Deep Models(Figure1, 最右侧) 进行联合训练,保证记忆能力与泛化能力的均衡, 提出Wide&Deep(Figure1, 中间)。

Wide为LR模型, 需要添加特征变换(transformed feature)来保证模型的memorization能力。Deep learning为DNN模型, 对稀疏以及未知的特征组合做低维嵌入保证模型的generalization(泛化, 归纳)能力。
1. The Wide Component
Wide 模型的定义(Linear Model):
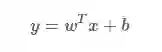
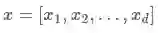
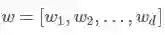
原始特征:User features(e.g., country, language, demographics),Contextual features(e.g., device, hour of the day, day of the week),Impression features(e.g., app age, historical statistics of an app)
转换特征:
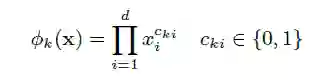
其中,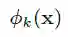
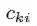
宽度模型使用多类型的叉乘特征变换,记忆特定的特征组合,但它的限制就是难以归纳以前没出现过的组合,那这就需要人工提供特征。
This captures the interactions between the binary features, and adds nonlinearity to the generalized linear model.
总结:宽度模型的输入是用户安装应用(installation)和为用户展示(impression)的应用间的向量积。
2. The Deep Component
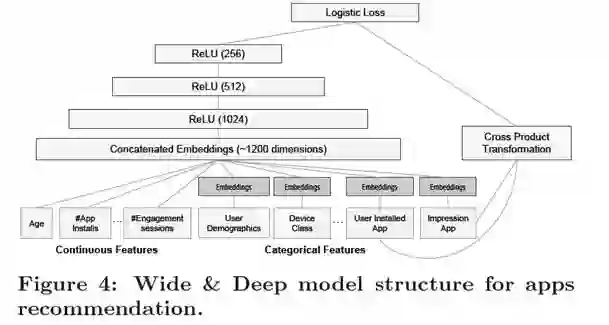
Figure1最右侧结构是一个3个hidden layer的MLP,其将类别特征(categorical feature),如安装了视频类应用,展示的是音乐类应用等,将这些高维稀疏的类别特征映射为低维稠密的向量(Dense Embeddings)。与其他连续特征(用户年龄、应用安装数等)拼接在一起,输入 MLP 中。
文中提到embedding维数为O(10)到O(100), embedding vector 进随机初始化等,隐含层的定义:
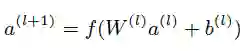
其中,l为hidden layer的层数,f为激活函数(ReLu)。 使用神经网络可以通过低维嵌入(lower dimension embedings)更好地归纳特征组合。
总结:基于 embedding 的深度模型的输入是 类别特征(产生embedding) + 连续特征。
3. Joint Training of Wide & Deep Model
文中提到Joint模型Wide与Deep,计算log odds ratio 然后加权求和。
并将Join与ensemble方式进行了对比:
Joint Training 同时训练 Wide & Deep 模型,优化的参数包括两个模型各自的参数以及 weights of sum
Ensemble 中的模型是分别独立训练的,互不干扰,只有在预测时才会联系在一起
Join可以大大减少在特征工程中构造cross-product feature的数量。该混合模型的表达式为:
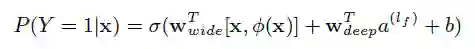
其中,Y 是二值类标签,表示用户是否下载app的行为。
4. SYSTEM IMPLEMENTATION
该Apps推荐系统主要包括数据生成, 模型训练, 模型服务三部分:
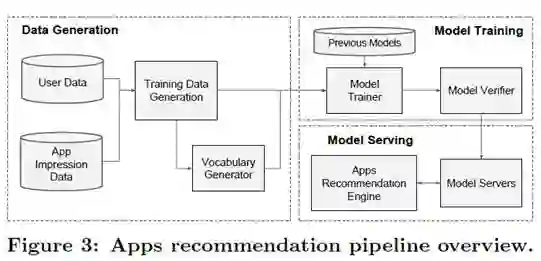
Data Generation
Label: 标准是 app acquisition,用户下载为 1,否则为 0。
Vocabularies: 将类别特征(categorical features)映射为整型的 id,连续的实值先用累计分布函数CDF归一化到[0,1],再划档离散化。
Model Training
500 billion的训练数据, Input layer 输入Continuous features 和 Categorical features,详情可参考Figure4. 在已经训练模型基础上,采用热启动的方式,也就是从之前的模型中读取 embeddings 以及 linear model weights来初始化一个新模型。当新的训练数据来临的时候,在已有模型的基础上进行训练,以减少计算的复杂度与时间开销。
Model Serving
当模型训练并且优化好之后,我们将它载入推荐引擎,对每一个query request,排序系统从检索系统接收候选列表,以及每一个app对应的特征,然后根据app特征通过Wide&Deep Model计算出每一个app分数,并由高到底排序。文中还提到使用更小的batchs与并行操作以提高推荐引擎的性能。
EXPERIMENT RESULTS
本文从app acquisitions 和 seving performance两个方面评估 Wide&Deep learning的效果。
app acquisitions:通过对1%的a线上用户进行A/B testing,Wide&Deep效果明显, 线下实现效果提升不大的原因可能是线下的实验数据是固定的, 限制了模型的泛化能力。实验效果见Table1:
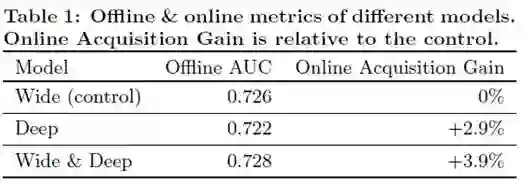
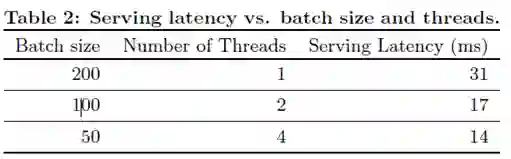
seving performance:工程现采用并行, 并使用较小的batch满足推荐引擎的高并发与低延迟的需求。实验效果见Table2:
REFERENCE
https://research.googleblog.com/2016/06/wide-deep-learning-better-together-with.html
http://www.shuang0420.com/2017/03/13/%E8%AE%BA%E6%96%87%E7%AC%94%E8%AE%B0%20-%20Wide%20and%20Deep%20Learning%20for%20Recommender%20Systems/
https://zhuanlan.zhihu.com/p/22597010
公众号回复“社区群”加入LibRec技术交流群,方便讨论学习。





