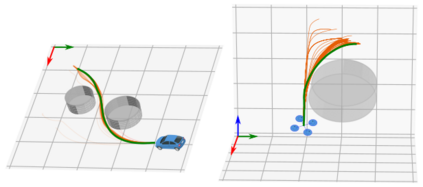
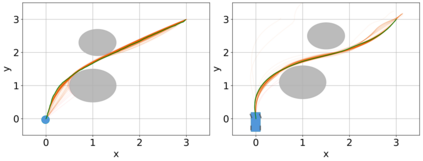
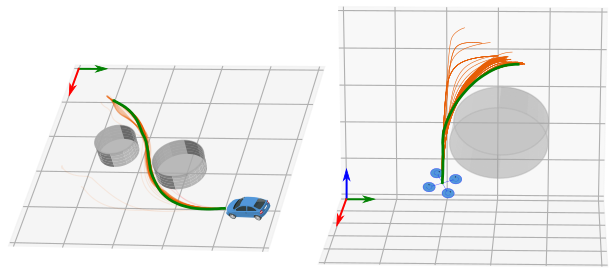
Safe operation of systems such as robots requires them to plan and execute trajectories subject to safety constraints. When those systems are subject to uncertainties in their dynamics, it is challenging to ensure that the constraints are not violated. In this paper, we propose Safe-CDDP, a safe trajectory optimization and control approach for systems under additive uncertainties and non-linear safety constraints based on constrained differential dynamic programming (DDP). The safety of the robot during its motion is formulated as chance constraints with user-chosen probabilities of constraint satisfaction. The chance constraints are transformed into deterministic ones in DDP formulation by constraint tightening. To avoid over-conservatism during constraint tightening, linear control gains of the feedback policy derived from the constrained DDP are used in the approximation of closed-loop uncertainty propagation in prediction. The proposed algorithm is empirically evaluated on three different robot dynamics with up to 12 degrees of freedom in simulation. The computational feasibility and applicability of the approach are demonstrated with a physical hardware implementation.
翻译:机器人等系统的安全操作要求它们规划和实施受安全限制的轨道。当这些系统在动态上受到不确定因素的影响时,确保这些限制因素不被违反是具有挑战性的。在本文件中,我们提议安全轨道优化和控制方法,即安全轨道优化和控制基于添加性不确定因素和非线性安全限制的系统,这种系统基于有限的不同动态编程(DDP),其运行过程中的机器人安全是用户选择的制约性满足可能性的概率限制。机会限制通过约束紧缩而转化为DDP制定过程中的确定性限制。为避免约束性紧缩期间过度保守,在预测中使用限制性DDP产生的反馈政策的线性控制收益来接近闭路不确定性的传播。拟议的算法是根据三种不同的机器人动态进行经验评估的,模拟自由度最高达12度。该方法的计算可行性和适用性通过硬件的安装得到证明。