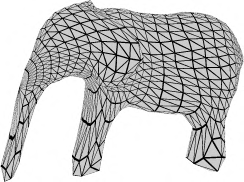
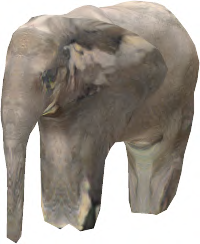
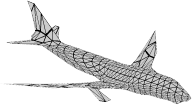
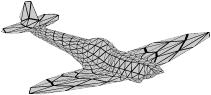
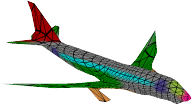
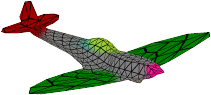
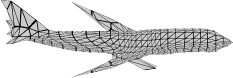
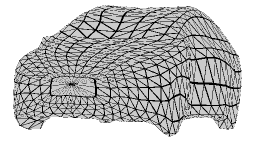
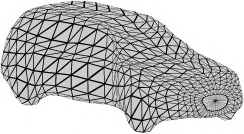
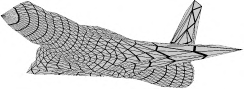
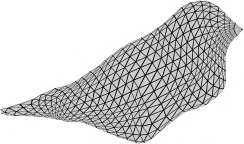
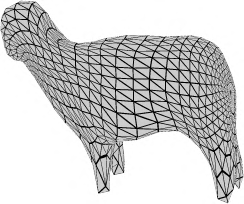
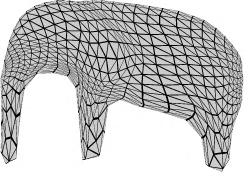
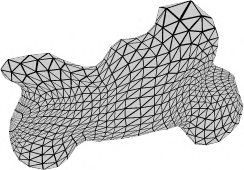
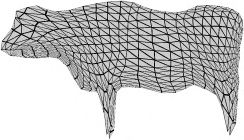
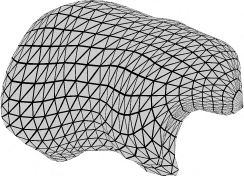
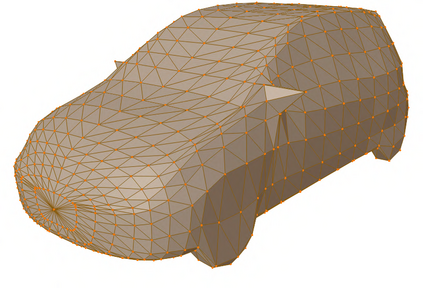
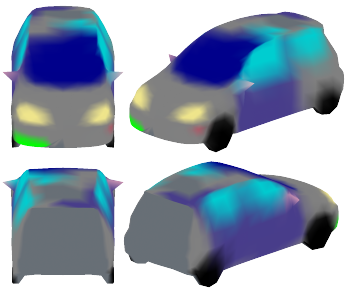
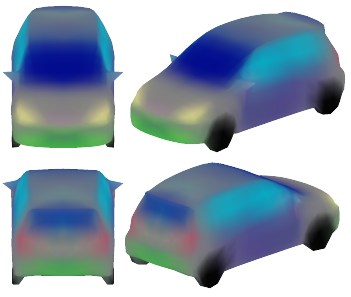
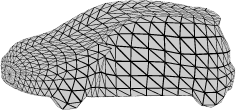
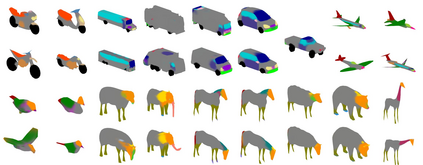
Recent advances in differentiable rendering have sparked an interest in learning generative models of textured 3D meshes from image collections. These models natively disentangle pose and appearance, enable downstream applications in computer graphics, and improve the ability of generative models to understand the concept of image formation. Although there has been prior work on learning such models from collections of 2D images, these approaches require a delicate pose estimation step that exploits annotated keypoints, thereby restricting their applicability to a few specific datasets. In this work, we propose a GAN framework for generating textured triangle meshes without relying on such annotations. We show that the performance of our approach is on par with prior work that relies on ground-truth keypoints, and more importantly, we demonstrate the generality of our method by setting new baselines on a larger set of categories from ImageNet - for which keypoints are not available - without any class-specific hyperparameter tuning. We release our code at https://github.com/dariopavllo/textured-3d-gan
翻译:不同图像的最近进步激发了人们对从图像收藏中学习3D模贝的纹理模型的基因化模型的兴趣。 这些模型原生地分解外观和外观,使计算机图形的下游应用成为下游应用,并提高基因化模型理解图像形成概念的能力。 虽然以前曾努力从2D图像的收集中学习这种模型,但这些方法需要一个微妙的外观估计步骤,利用附加注释的钥匙点,从而限制其适用于几个特定的数据集。在这项工作中,我们提议了一个GAN框架,用于生成纹理三角模贝,而不必依赖这种说明。我们表明,我们的方法与以前依赖地面图象关键点的工作是完全相同的,更重要的是,我们通过在图像网的更多类别上设定新的基线来显示我们方法的通用性,而对于这些类别,没有关键点可供使用——在没有任何特定等级的超参数调制。我们在 https://github.com/darivollo/textured-3dgan上公布了我们的代码。