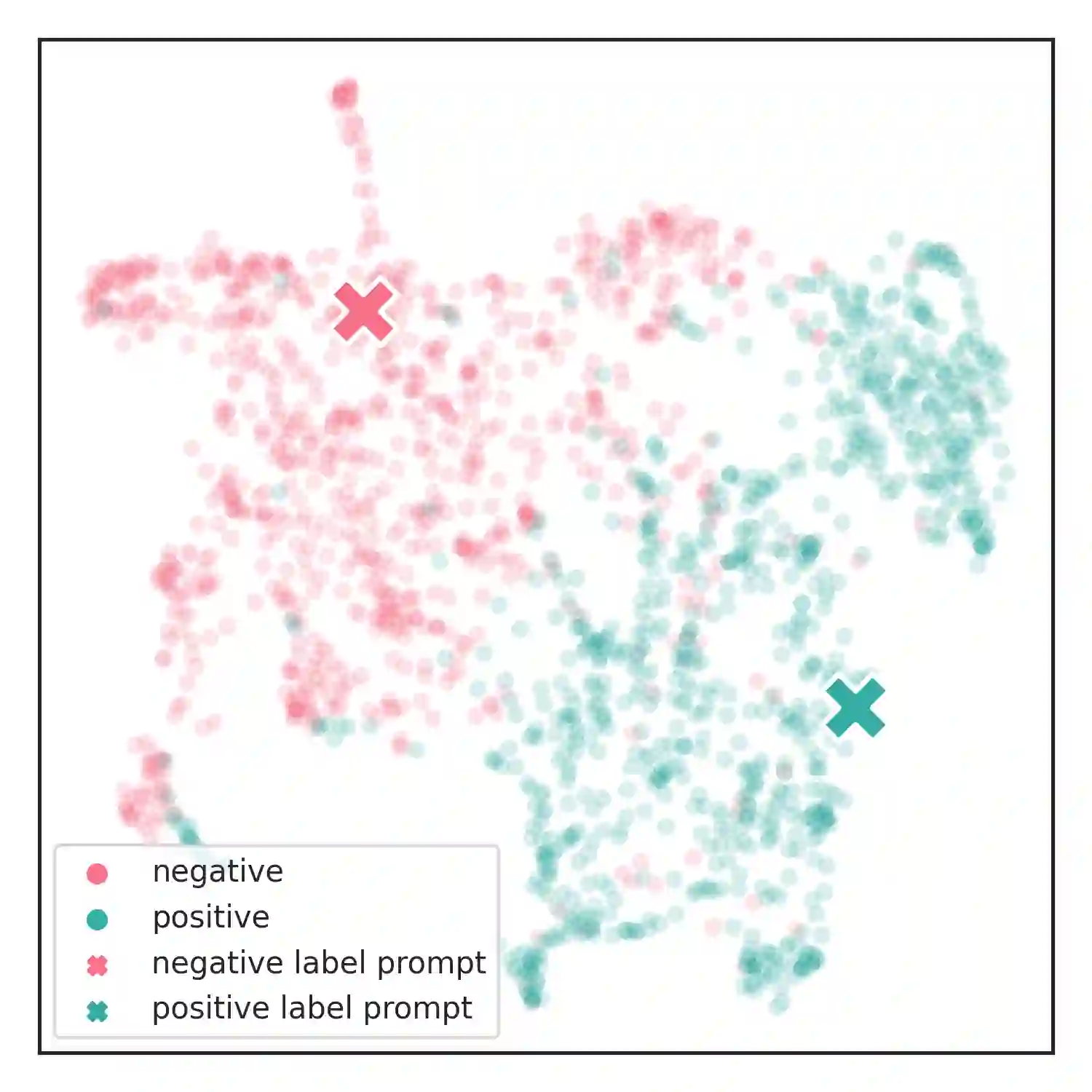
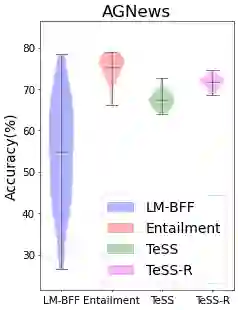
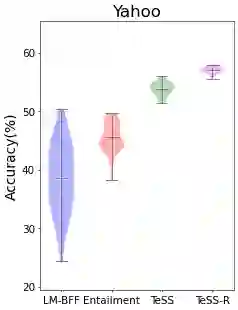
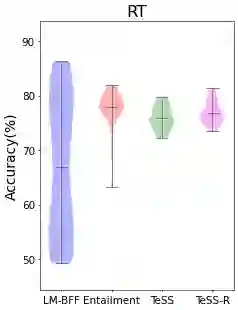
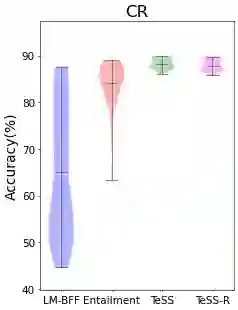
We introduce TeSS (Text Similarity Comparison using Sentence Encoder), a framework for zero-shot classification where the assigned label is determined by the embedding similarity between the input text and each candidate label prompt. We leverage representations from sentence encoders optimized to locate semantically similar samples closer to each other in embedding space during pre-training. The label prompt embeddings serve as prototypes of their corresponding class clusters. Furthermore, to compensate for the potentially poorly descriptive labels in their original format, we retrieve semantically similar sentences from external corpora and additionally use them with the original label prompt (TeSS-R). TeSS outperforms strong baselines on various closed-set and open-set classification datasets under zero-shot setting, with further gains when combined with label prompt diversification through retrieval. These results are robustly attained to verbalizer variations, an ancillary benefit of using a bi-encoder. Altogether, our method serves as a reliable baseline for zero-shot classification and a simple interface to assess the quality of sentence encoders.
翻译:我们引入了TESS(使用句子编码器进行线性相似性比较),这是一个零点分类框架,指定标签是通过输入文本和每个候选标签的相似性嵌入的。我们优化了句子编码器的演示,在培训前嵌入空间时,将语义相似的样本定位到彼此更接近的位置。标签提示嵌入作为相应类群的原原样。此外,为了弥补最初格式的描述性标签可能很差,我们从外部公司取回语义相似的句子,并用原标签提示(TeSS-R)进一步使用这些句子。 TESS在零点设置下,在各种封闭和开放的分类数据集上超越了强大的基线,在与通过检索的标签快速多样化相结合时还取得了进一步收益。这些结果被强有力地接受了语言变异,这是使用双分解器的辅助好处。加在一起,我们的方法可以作为零点分类的可靠基线和一个简单的界面,用来评估句子编码器的质量。