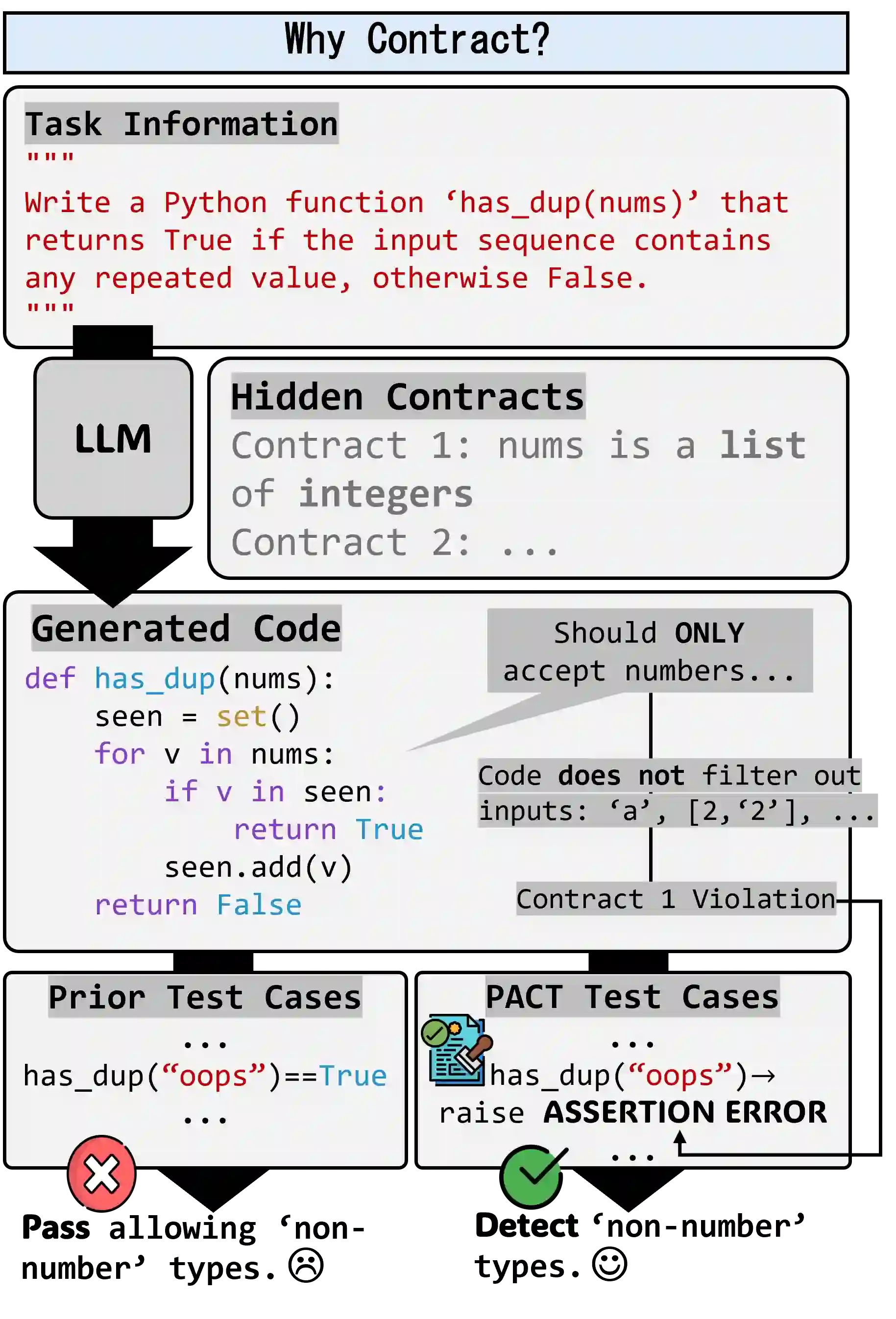
Prevailing code generation benchmarks, such as HumanEval+ and MBPP+, primarily evaluate large language models (LLMs) with pass@k on functional correctness using well-formed inputs. However, they ignore a crucial aspect of real-world software: adherence to contracts-the preconditions and validity constraints that dictate how ill-formed inputs must be rejected. This critical oversight means that existing benchmarks fail to measure, and models consequently fail to generate, truly robust and reliable code snippets. We introduce PACT, a program assessment and contract-adherence evaluation framework, to bridge this gap. PACT is the first framework designed to systematically evaluate and enhance contract-adherence in LLM-generated code snippets alongside functional correctness. PACT's contributions are threefold: First, it provides a comprehensive test-suite corpus focused on contract violations, extending HumanEval+ and MBPP+. Second, it enables a systematic analysis of code generation under varied prompting conditions. This analysis demonstrates that augmenting prompts with contract-violating test cases significantly enhance a model's ability to respect contracts compared to using contract description alone. Finally, it introduces novel metrics to rigorously quantify contract adherence in both test generation and code generation. By revealing critical errors that conventional benchmarks overlook, PACT provides the rigorous and interpretable metrics to evaluate the robustness of LLM-generated code snippets in both functionality and contract-adherence. Our code and data are available at https://github.com/suhanmen/PACT.
翻译:暂无翻译