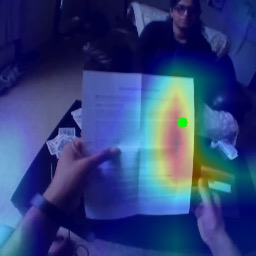
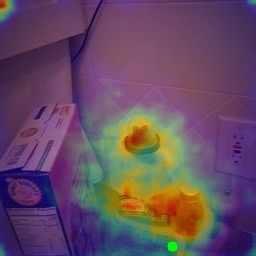
In this paper, we present the first transformer-based model to address the challenging problem of egocentric gaze estimation. We observe that the connection between the global scene context and local visual information is vital for localizing the gaze fixation from egocentric video frames. To this end, we design the transformer encoder to embed the global context as one additional visual token and further propose a novel Global-Local Correlation (GLC) module to explicitly model the correlation of the global token and each local token. We validate our model on two egocentric video datasets - EGTEA Gaze+ and Ego4D. Our detailed ablation studies demonstrate the benefits of our method. In addition, our approach exceeds previous state-of-the-arts by a large margin. We also provide additional visualizations to support our claim that global-local correlation serves a key representation for predicting gaze fixation from egocentric videos. More details can be found in our website (https://bolinlai.github.io/GLC-EgoGazeEst).
翻译:在本文中,我们展示了第一个基于变压器的模型,以解决以自我为中心的视觉估计这一具有挑战性的问题。我们观察到,全球场景背景与当地视觉信息之间的联系对于从以自我为中心的视频框中确定视像固定位置至关重要。为此,我们设计了变压器编码器,将全球背景嵌入为另一个视觉象征,并进一步提出一个新的全球-地方关系模块,以明确模拟全球象征和每个地方象征的关联性。我们验证了我们两个以自我为中心的视频数据集的模型-EGTEA Gaze+和Ego4D。我们的详细对比研究展示了我们的方法的好处。此外,我们的方法大大超出了以往的艺术状态。我们还提供了更多的可视化支持我们的说法,即全球-地方关系为预测以自我中心视频进行视像固定提供了关键代表。更多的细节可以在我们的网站(https://bolinlai.github.io/GLC-EgoGazeEst)中找到。