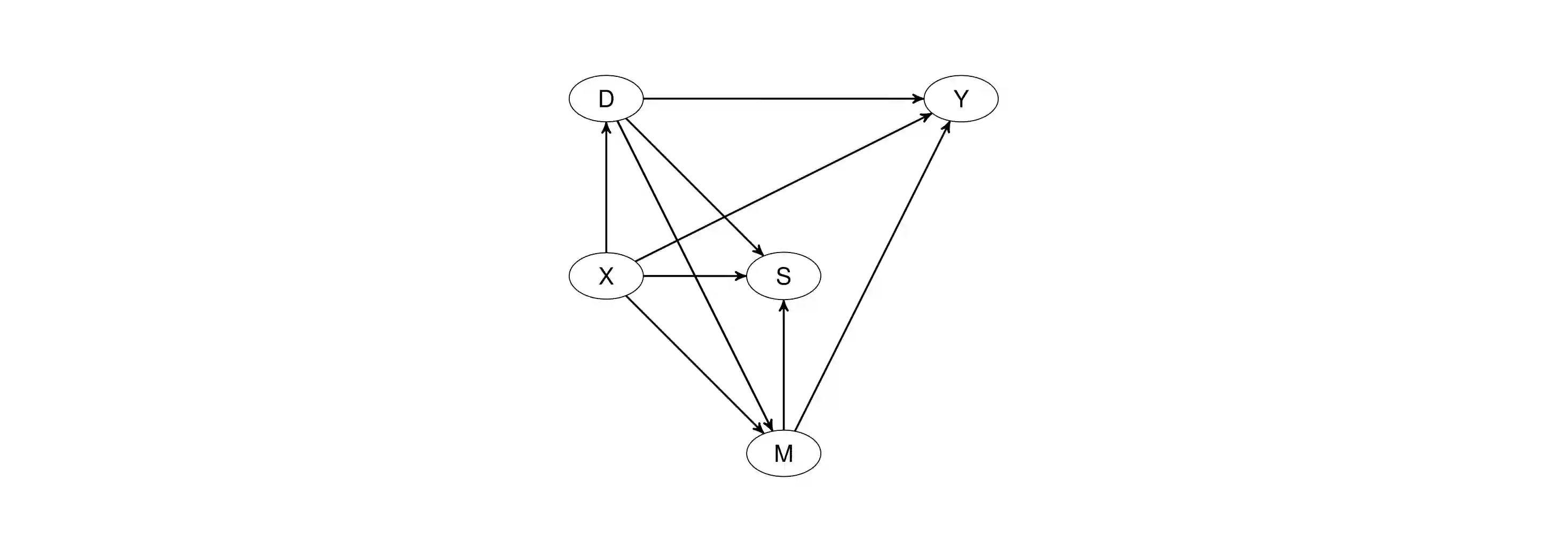
This paper considers the evaluation of discretely distributed treatments when outcomes are only observed for a subpopulation due to sample selection or outcome attrition. For identification, we combine a selection-on-observables assumption for treatment assignment with either selection-on-observables or instrumental variable assumptions concerning the outcome attrition/sample selection process. We also consider dynamic confounding, meaning that covariates that jointly affect sample selection and the outcome may (at least partly) be influenced by the treatment. To control in a data-driven way for a potentially high dimensional set of pre- and/or post-treatment covariates, we adapt the double machine learning framework for treatment evaluation to sample selection problems. We make use of (a) Neyman-orthogonal, doubly robust, and efficient score functions, which imply the robustness of treatment effect estimation to moderate regularization biases in the machine learning-based estimation of the outcome, treatment, or sample selection models and (b) sample splitting (or cross-fitting) to prevent overfitting bias. We demonstrate that the proposed estimators are asymptotically normal and root-n consistent under specific regularity conditions concerning the machine learners and investigate their finite sample properties in a simulation study. We also apply our proposed methodology to the Job Corps data for evaluating the effect of training on hourly wages which are only observed conditional on employment. The estimator is available in the causalweight package for the statistical software R.
翻译:本文考虑在因抽样选择或结果减耗而仅观察到某一子人群的结果时,对分散的治疗进行评价; 为了确定,我们将治疗任务选择的可观察假设与结果自然减员/抽样选择过程的可观察选择或工具变量假设结合起来; 我们还考虑动态混杂,这意味着共同影响抽样选择和结果的共变体可能(至少部分)受到治疗的影响; 为了控制可能具有较高尺寸的治疗前和/或后处理常变体的数据驱动,我们将治疗评价的双机学习框架调整为抽样选择问题; 我们使用(a) 内曼-奥多博纳、双倍强和高效得分功能,这意味着治疗效果估计的稳健性,以在机床学习对结果、治疗或抽样选择模式的估计中,适度地调整偏差;(b) 抽样分离(或仅相互校正),以防止过度的偏差。 我们表明,拟议的估算师对治疗评价的双重机床评估框架的正常和根基学习框架,我们还在具体的统计数据中定期评估其定额学习者的统计方法。