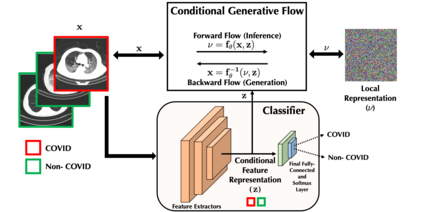
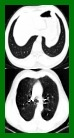
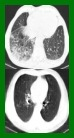
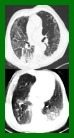
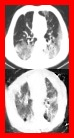
$\textbf{Background:}$ At the onset of a pandemic, such as COVID-19, data with proper labeling/attributes corresponding to the new disease might be unavailable or sparse. Machine Learning (ML) models trained with the available data, which is limited in quantity and poor in diversity, will often be biased and inaccurate. At the same time, ML algorithms designed to fight pandemics must have good performance and be developed in a time-sensitive manner. To tackle the challenges of limited data, and label scarcity in the available data, we propose generating conditional synthetic data, to be used alongside real data for developing robust ML models. $\textbf{Methods:}$ We present a hybrid model consisting of a conditional generative flow and a classifier for conditional synthetic data generation. The classifier decouples the feature representation for the condition, which is fed to the flow to extract the local noise. We generate synthetic data by manipulating the local noise with fixed conditional feature representation. We also propose a semi-supervised approach to generate synthetic samples in the absence of labels for a majority of the available data. $\textbf{Results:}$ We performed conditional synthetic generation for chest computed tomography (CT) scans corresponding to normal, COVID-19, and pneumonia afflicted patients. We show that our method significantly outperforms existing models both on qualitative and quantitative performance, and our semi-supervised approach can efficiently synthesize conditional samples under label scarcity. As an example of downstream use of synthetic data, we show improvement in COVID-19 detection from CT scans with conditional synthetic data augmentation.
翻译:$\ textbf{ background:}$$美元 在传染病爆发时,例如COVID-19, 配有与新疾病相对应的正确标签/属性的数据可能不存在或稀少。 用现有数据培训的机器学习(ML)模型,其数量有限,多样性差,往往是偏差和不准确的。与此同时,旨在防治流行病的ML算法必须具有良好的性能,并且以对时间敏感的方式发展。为了应对有限数据的挑战,并对现有数据进行分类,我们提议在开发稳健的ML模型时使用有条件的合成数据。 $\ textbf{Methods:$look:$ld:我们展示一种有条件的基因化流和分类模型的混合模型,我们目前用于模拟的DNA数据,我们用来模拟的Mexcial-loral-loral exalalal 。