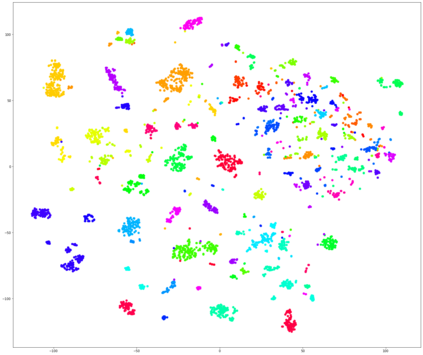
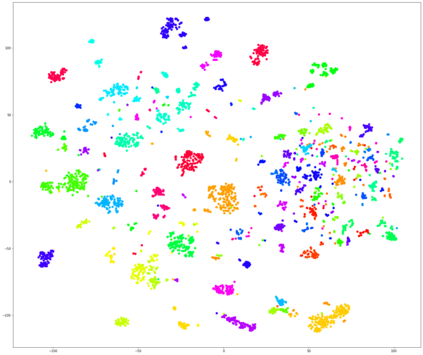
In our recent dietary assessment field studies on passive dietary monitoring in Ghana, we have collected over 250k in-the-wild images. The dataset is an ongoing effort to facilitate accurate measurement of individual food and nutrient intake in low and middle income countries with passive monitoring camera technologies. The current dataset involves 20 households (74 subjects) from both the rural and urban regions of Ghana, and two different types of wearable cameras were used in the studies. Once initiated, wearable cameras continuously capture subjects' activities, which yield massive amounts of data to be cleaned and annotated before analysis is conducted. To ease the data post-processing and annotation tasks, we propose a novel self-supervised learning framework to cluster the large volume of egocentric images into separate events. Each event consists of a sequence of temporally continuous and contextually similar images. By clustering images into separate events, annotators and dietitians can examine and analyze the data more efficiently and facilitate the subsequent dietary assessment processes. Validated on a held-out test set with ground truth labels, the proposed framework outperforms baselines in terms of clustering quality and classification accuracy.
翻译:在最近对加纳被动饮食监测进行的饮食评估实地研究中,我们收集了250公里的全方位图像。数据集是一项持续的努力,目的是利用被动监测相机技术,促进准确测量中低收入国家个人食物和营养摄入量。目前的数据集涉及加纳农村和城市地区的20个住户(74个对象),在研究中使用了两种不同的可磨损照相机。一旦启动,可磨损的照相机不断捕捉对象的活动,这些活动产生大量数据需要清理并在进行分析之前附加说明。为了减轻数据后处理和注释的任务,我们提出了一个新的自我监督学习框架,将大量以自我为中心的图像分组成不同的事件。每个事件都由一系列时间连续和背景相似的图像组成。通过将图像分组成不同的事件,说明员和饮食学家可以更高效地检查和分析数据,并便利随后的饮食评估进程。在现场真相标签的搁置测试中验证,拟议的框架在分组质量和分类方面超越了基线。