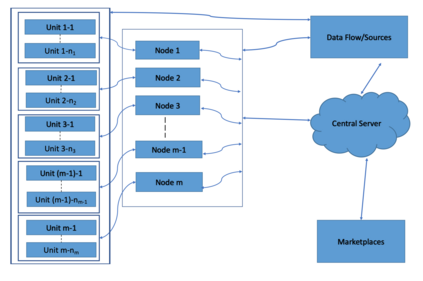
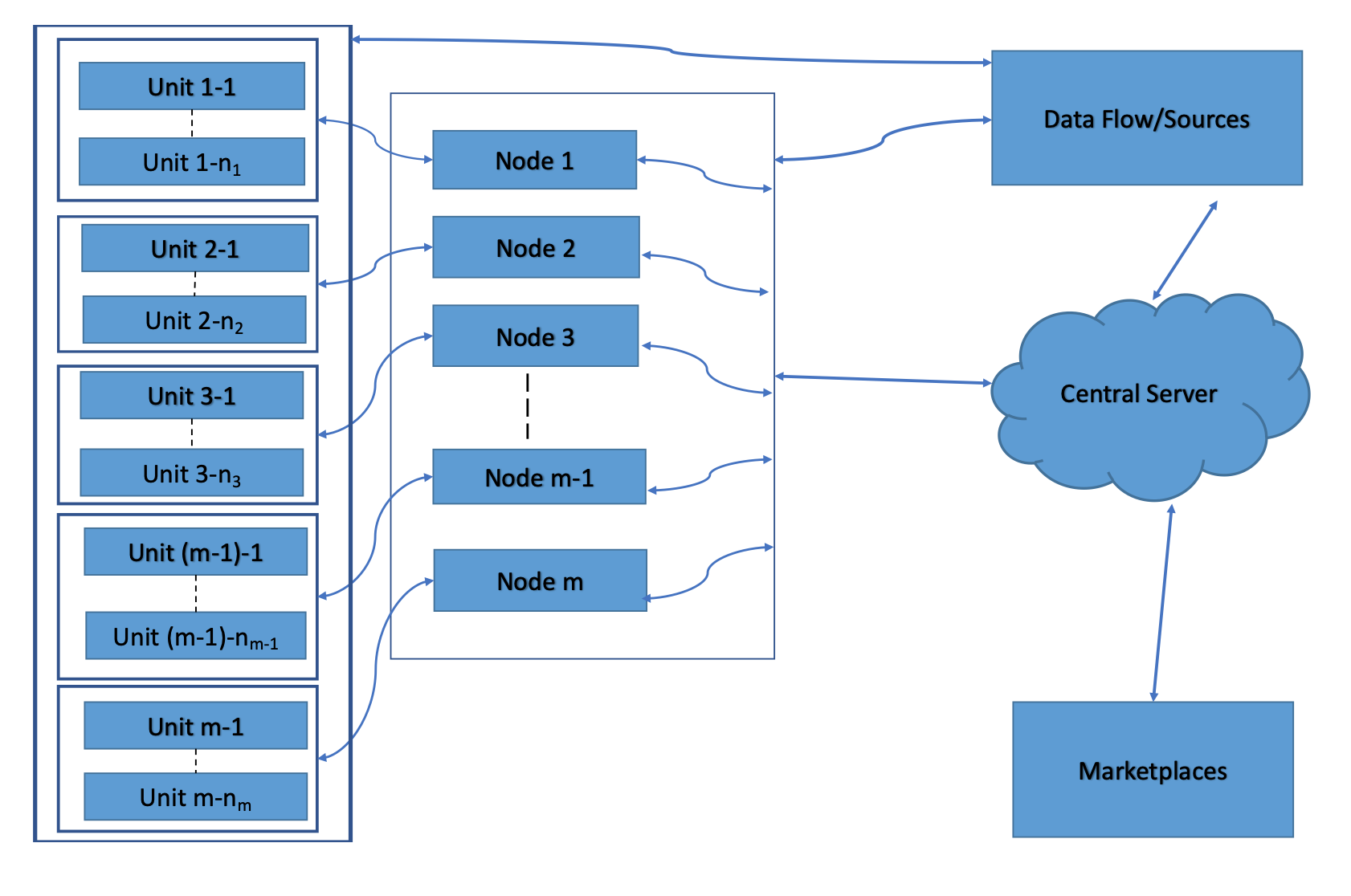
This paper proposes a hierarchical approximate-factor approach to analyzing high-dimensional, large-scale heterogeneous time series data using distributed computing. The new method employs a multiple-fold dimension reduction procedure using Principal Component Analysis (PCA) and shows great promises for modeling large-scale data that cannot be stored nor analyzed by a single machine. Each computer at the basic level performs a PCA to extract common factors among the time series assigned to it and transfers those factors to one and only one node of the second level. Each 2nd-level computer collects the common factors from its subordinates and performs another PCA to select the 2nd-level common factors. This process is repeated until the central server is reached, which collects common factors from its direct subordinates and performs a final PCA to select the global common factors. The noise terms of the 2nd-level approximate factor model are the unique common factors of the 1st-level clusters. We focus on the case of 2 levels in our theoretical derivations, but the idea can easily be generalized to any finite number of hierarchies. We discuss some clustering methods when the group memberships are unknown and introduce a new diffusion index approach to forecasting. We further extend the analysis to unit-root nonstationary time series. Asymptotic properties of the proposed method are derived for the diverging dimension of the data in each computing unit and the sample size $T$. We use both simulated data and real examples to assess the performance of the proposed method in finite samples, and compare our method with the commonly used ones in the literature concerning the forecastability of extracted factors.
翻译:本文提出了使用分布式计算分析高维、大比例混混时间序列数据的等级近因法方法。 新方法使用主元件分析( PCA) 采用多维递减程序, 并展示了制作无法存储或由一台机器分析的大型数据模型的巨大前景。 基本级别的每台计算机都使用五氯苯甲醚来提取分配给它的时间序列中的共同因素, 并将这些因素转移到第二层的一个节点。 每2级计算机都收集其下属的共同因素, 并使用另一个常设仲裁机构来选择第2级共同因素。 这一过程在中央服务器完成之前重复进行, 中央服务器从直接的下属收集共同因素, 并运行最后的常设仲裁机构来选择全球共同因素。 2级的近因数模型的噪音是第1级组的独特共同因素, 并将这些因素转移到我们理论衍生的2级, 但这一想法很容易被概括到任何有限的等级因素。 当小组成员未知时, 我们讨论一些组合方法, 并在中央服务器完成中央级服务器, 收集其直接下属的常见因素, 并进行最后的常设常设常设常设的常设的常设的常设的常设指数方法 。 我们进一步分析, 将模型的计算方法 。