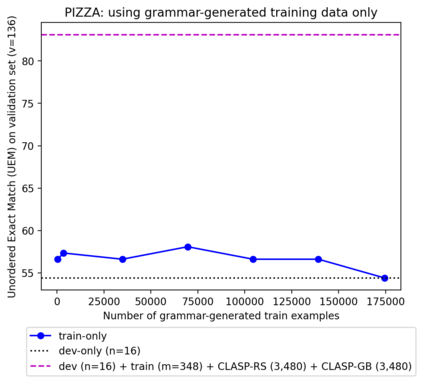
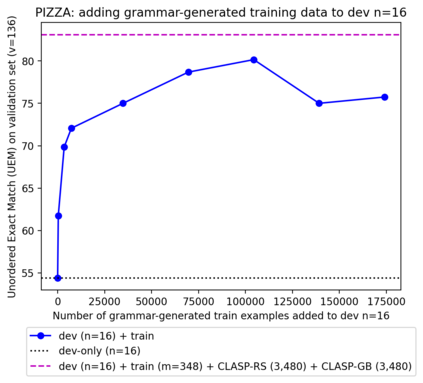
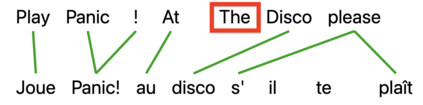
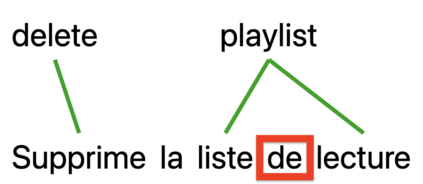
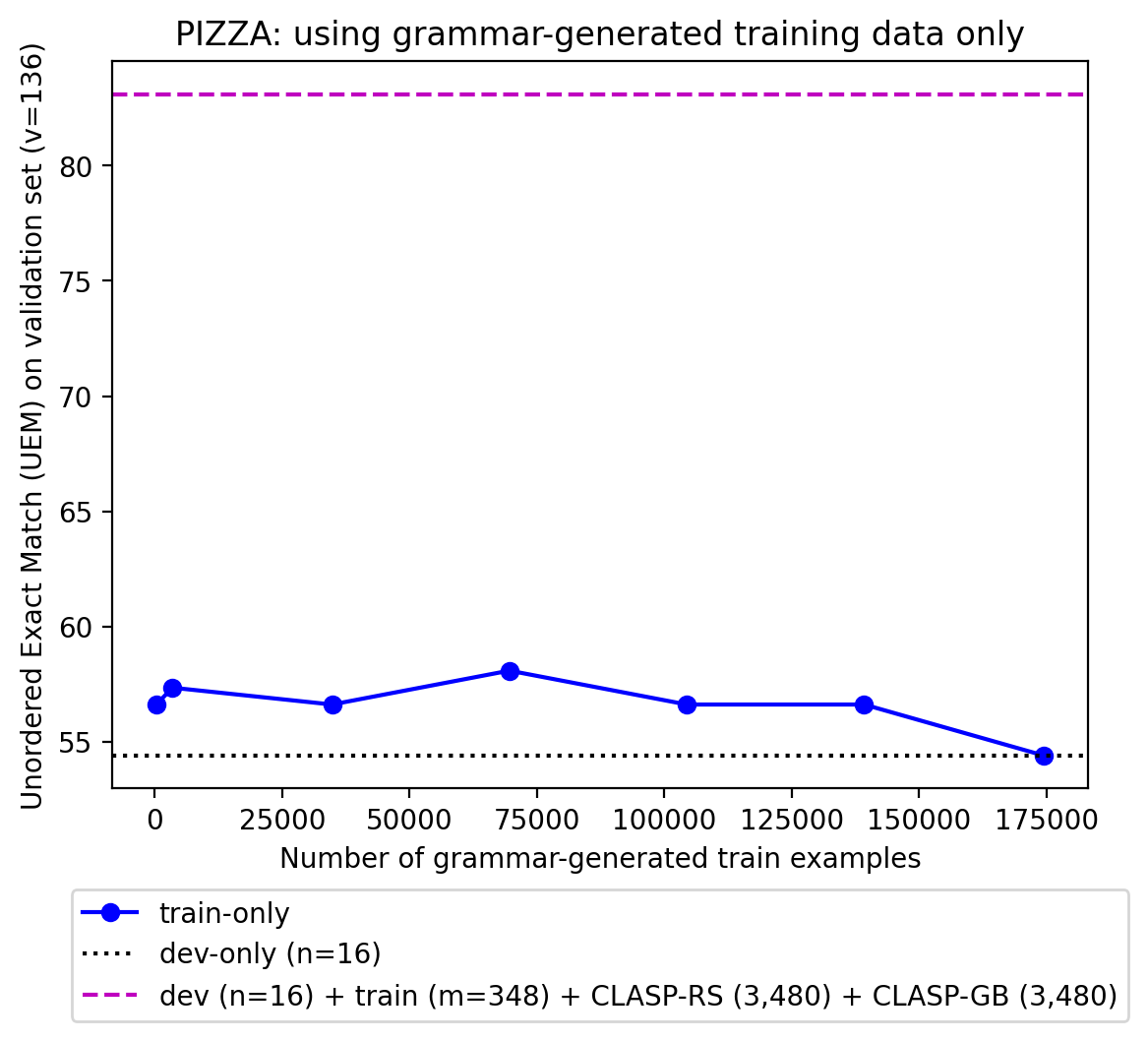
A bottleneck to developing Semantic Parsing (SP) models is the need for a large volume of human-labeled training data. Given the complexity and cost of human annotation for SP, labeled data is often scarce, particularly in multilingual settings. Large Language Models (LLMs) excel at SP given only a few examples, however LLMs are unsuitable for runtime systems which require low latency. In this work, we propose CLASP, a simple method to improve low-resource SP for moderate-sized models: we generate synthetic data from AlexaTM 20B to augment the training set for a model 40x smaller (500M parameters). We evaluate on two datasets in low-resource settings: English PIZZA, containing either 348 or 16 real examples, and mTOP cross-lingual zero-shot, where training data is available only in English, and the model must generalize to four new languages. On both datasets, we show significant improvements over strong baseline methods.
翻译:开发语义分解(SP)模型的一个瓶颈是需要大量的人类标签培训数据。鉴于人类对SP的批注的复杂性和成本,标签数据往往很少,特别是在多语种环境中。大型语言模型(LLMS)在SP中仅举几个例子,大语言模型(LLMS)优于SP,但是LLMS不适合运行时间系统,而运行时间系统需要低潜伏。在这项工作中,我们建议CLASP,这是改进中小型模型的低资源SP的一个简单方法:我们从AlexaTM 20B中生成合成数据,以扩大模型40x较小(500M参数)的培训集。我们评估了在低资源环境中的两个数据集:英文 PIZZA, 包含348或16个真实例子,以及 mTOP跨语言零弹,只有英语培训数据,而模型必须概括为四种新语言。在这两个数据集中,我们展示了强基线方法方面的显著改进。