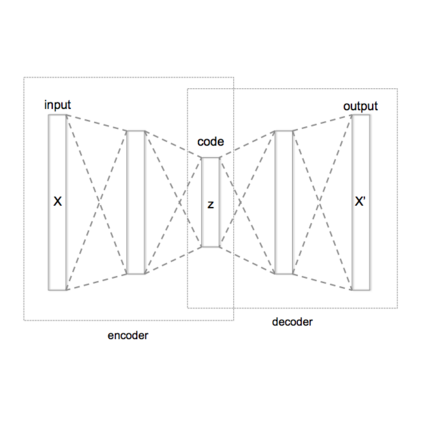
We study a challenging task, conditional human motion generation, which produces plausible human motion sequences according to various conditional inputs, such as action classes or textual descriptors. Since human motions are highly diverse and have a property of quite different distribution from conditional modalities, such as textual descriptors in natural languages, it is hard to learn a probabilistic mapping from the desired conditional modality to the human motion sequences. Besides, the raw motion data from the motion capture system might be redundant in sequences and contain noises; directly modeling the joint distribution over the raw motion sequences and conditional modalities would need a heavy computational overhead and might result in artifacts introduced by the captured noises. To learn a better representation of the various human motion sequences, we first design a powerful Variational AutoEncoder (VAE) and arrive at a representative and low-dimensional latent code for a human motion sequence. Then, instead of using a diffusion model to establish the connections between the raw motion sequences and the conditional inputs, we perform a diffusion process on the motion latent space. Our proposed Motion Latent-based Diffusion model (MLD) could produce vivid motion sequences conforming to the given conditional inputs and substantially reduce the computational overhead in both the training and inference stages. Extensive experiments on various human motion generation tasks demonstrate that our MLD achieves significant improvements over the state-of-the-art methods among extensive human motion generation tasks, with two orders of magnitude faster than previous diffusion models on raw motion sequences.
翻译:我们研究了一项具有挑战性的任务,即有条件的人体运动生成,根据各种条件输入(例如动作类别或文本描述),生成合理的人体运动序列。由于人体运动具有高度多样性,并且与条件模态(例如自然语言中的文本描述)具有相当不同的分布属性,因此很难学习从所需条件模态到人体运动序列的概率映射。此外,来自运动捕捉系统的原始运动数据可能在序列中冗余,并且包含噪音;直接建模序列和条件模态上的联合分布将需要大量计算开销,并可能导致引入的噪声伪影。为了学习人体运动序列的更好表示,我们首先设计了一个强大的变分自编码器(VAE),并得到人体运动序列的代表性和低维潜在编码。然后,我们使用行动潜在空间上的扩散过程,而不是使用扩散模型来建立原始运动序列和条件输入之间的连接。我们提出的基于运动潜空间的扩散模型(MLD)可以生成符合给定条件输入的生动运动序列,并极大地降低了训练和推理阶段的计算开销。对各种人体运动生成任务的广泛实验表明,我们的MLD在广泛的人体运动生成任务中都取得了显著的改进,并且比以前的扩散模型在原始运动序列上快了两个数量级。