给我1张图,生成30秒视频!|DeepMind新作

新智元报道
新智元报道
【新智元导读】近日,DeepMind提出了一种基于概率帧预测的图像建模和视觉任务的通用框架——Transframer。


Transframer架构

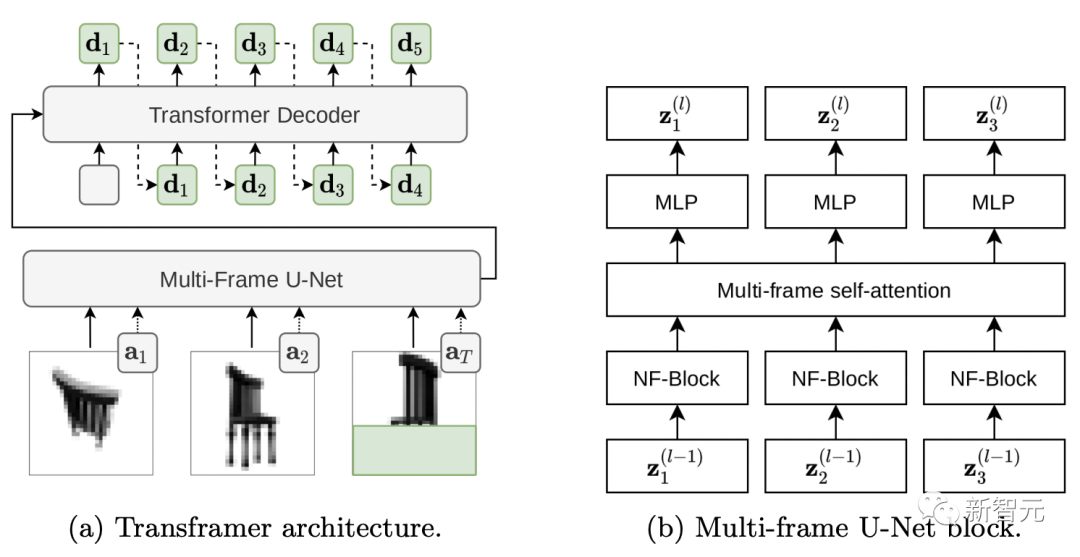
(a)Transframer将DCT图像(a1和a2)以及部分隐藏的目标DCT图像(aT)和附加注释作为输入,由多帧U-Net编码器处理。 接下来,U-Net输出通过交叉注意力传递给DC-Transformer解码器,该解码器则自动回归生成与目标图像的隐藏部分对应的DCT Token序列(绿色字母)。 (b)多帧U-Net block由NF-Net卷积块、多帧自注意力块组成,它们在输入帧之间交换信息和 Transformer式的残差MLP。
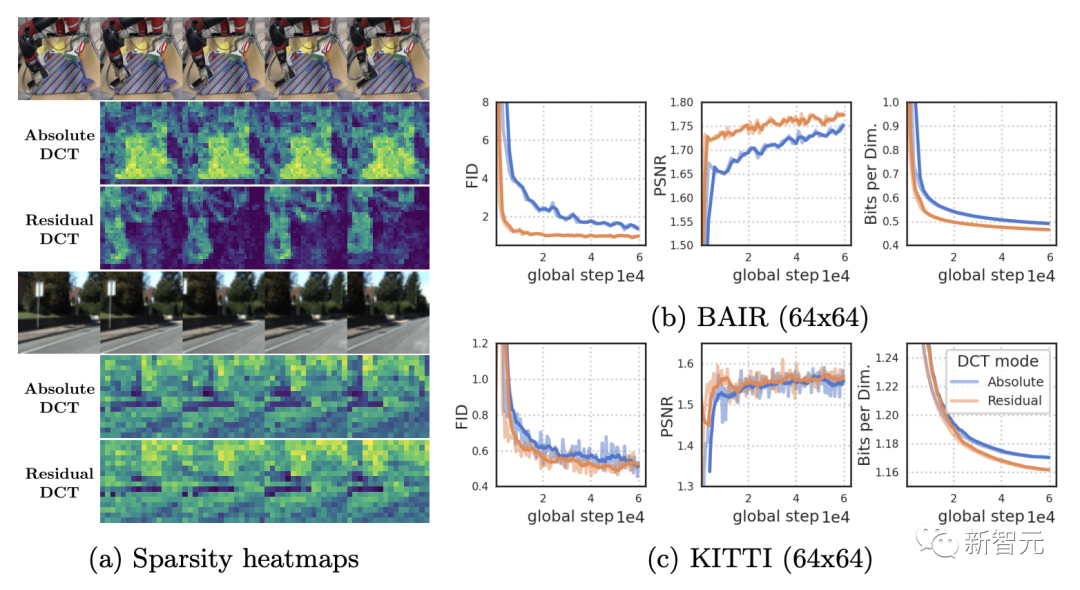
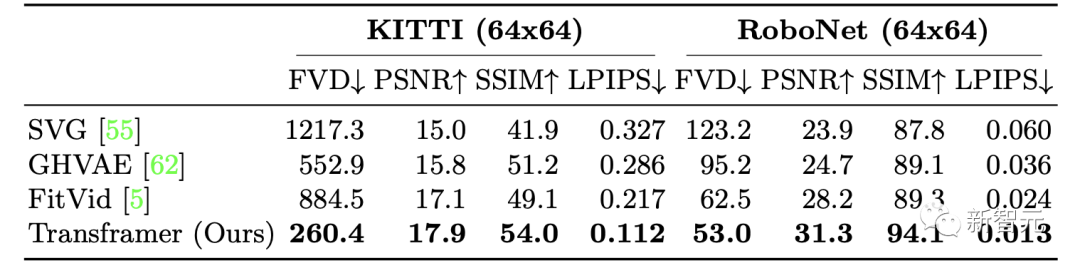
多视觉任务强者




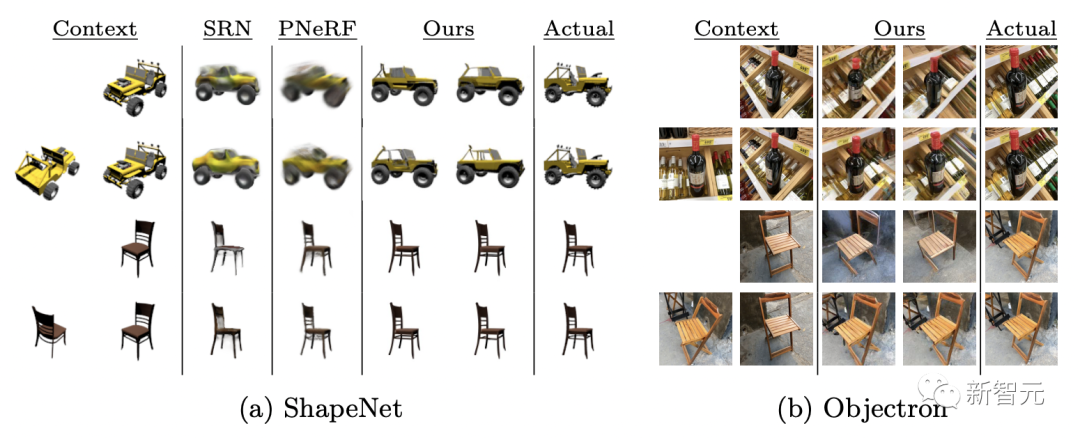

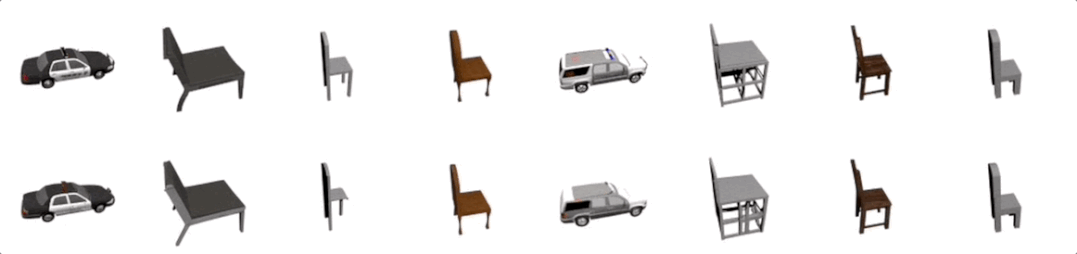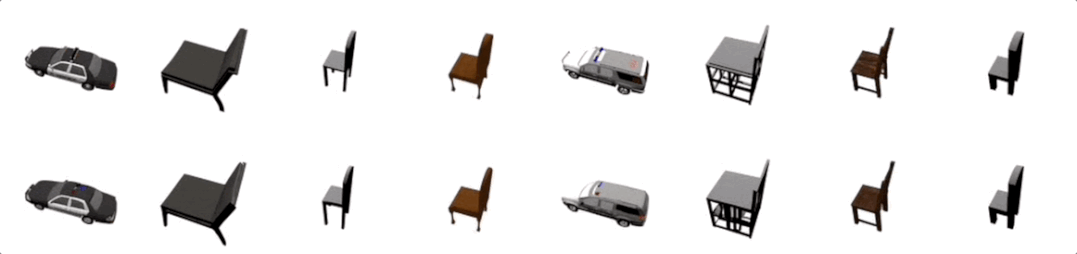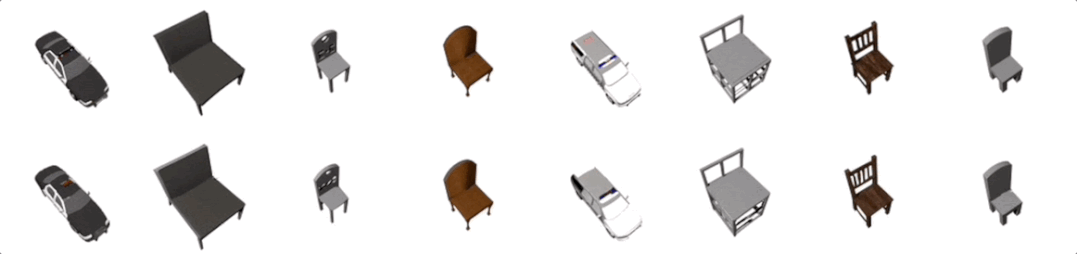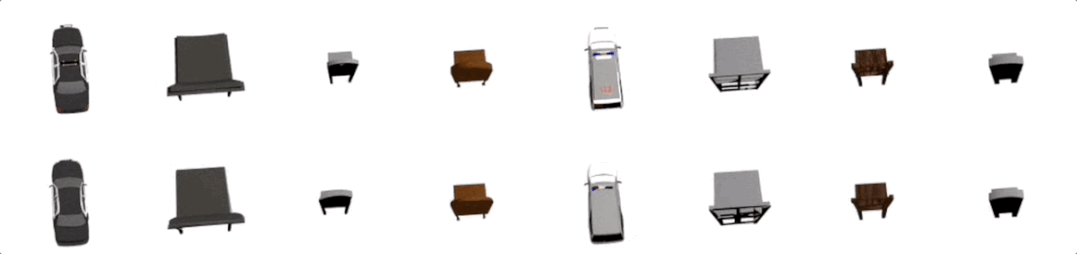





登录查看更多
相关内容

Framer Studio is built on
Framer.js, an open source framework for rapid prototyping. Framer allows you to define animations and interactions. It runs on mobile devices, too.
Source: Framer – Innovative Prototyping
专知会员服务
13+阅读 · 2020年3月12日
专知会员服务
43+阅读 · 2020年1月28日
Arxiv
10+阅读 · 2020年3月13日

相关VIP内容
专知会员服务
13+阅读 · 2020年3月12日
专知会员服务
43+阅读 · 2020年1月28日
相关资讯
相关论文
Arxiv
10+阅读 · 2020年3月13日