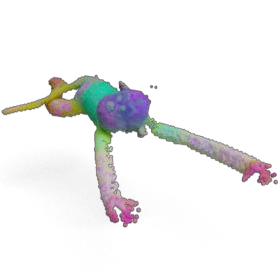
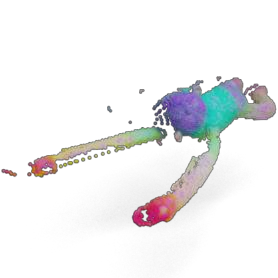
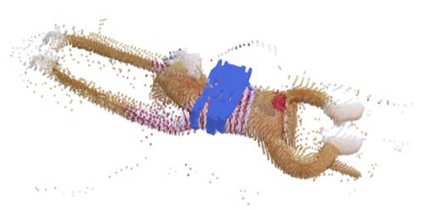
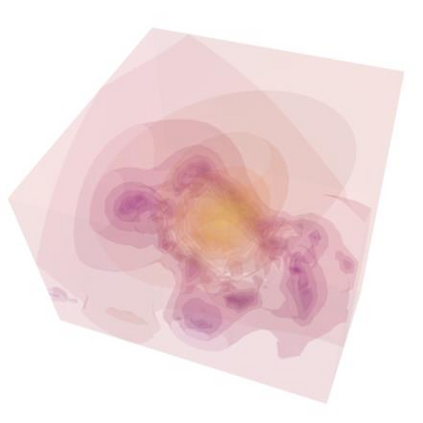
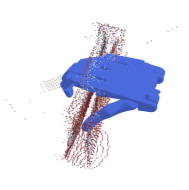
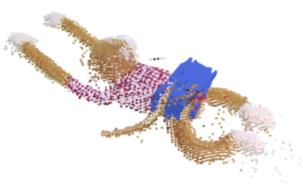
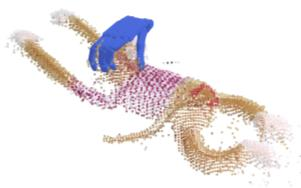
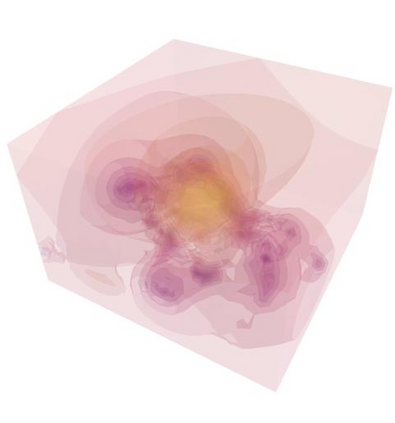
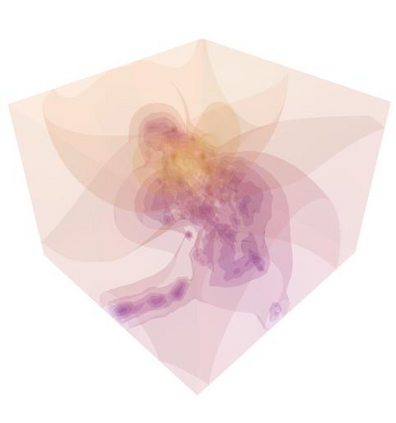
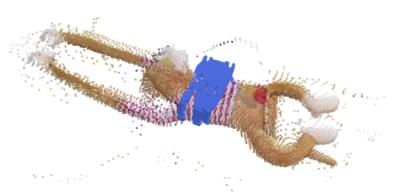
Humans excel at transferring manipulation skills across diverse object shapes, poses, and appearances due to their understanding of semantic correspondences between different instances. To endow robots with a similar high-level understanding, we develop a Distilled Feature Field (DFF) for 3D scenes, leveraging large 2D vision models to distill semantic features from multiview images. While current research demonstrates advanced performance in reconstructing DFFs from dense views, the development of learning a DFF from sparse views is relatively nascent, despite its prevalence in numerous manipulation tasks with fixed cameras. In this work, we introduce SparseDFF, a novel method for acquiring view-consistent 3D DFFs from sparse RGBD observations, enabling one-shot learning of dexterous manipulations that are transferable to novel scenes. Specifically, we map the image features to the 3D point cloud, allowing for propagation across the 3D space to establish a dense feature field. At the core of SparseDFF is a lightweight feature refinement network, optimized with a contrastive loss between pairwise views after back-projecting the image features onto the 3D point cloud. Additionally, we implement a point-pruning mechanism to augment feature continuity within each local neighborhood. By establishing coherent feature fields on both source and target scenes, we devise an energy function that facilitates the minimization of feature discrepancies w.r.t. the end-effector parameters between the demonstration and the target manipulation. We evaluate our approach using a dexterous hand, mastering real-world manipulations on both rigid and deformable objects, and showcase robust generalization in the face of object and scene-context variations.
翻译:暂无翻译