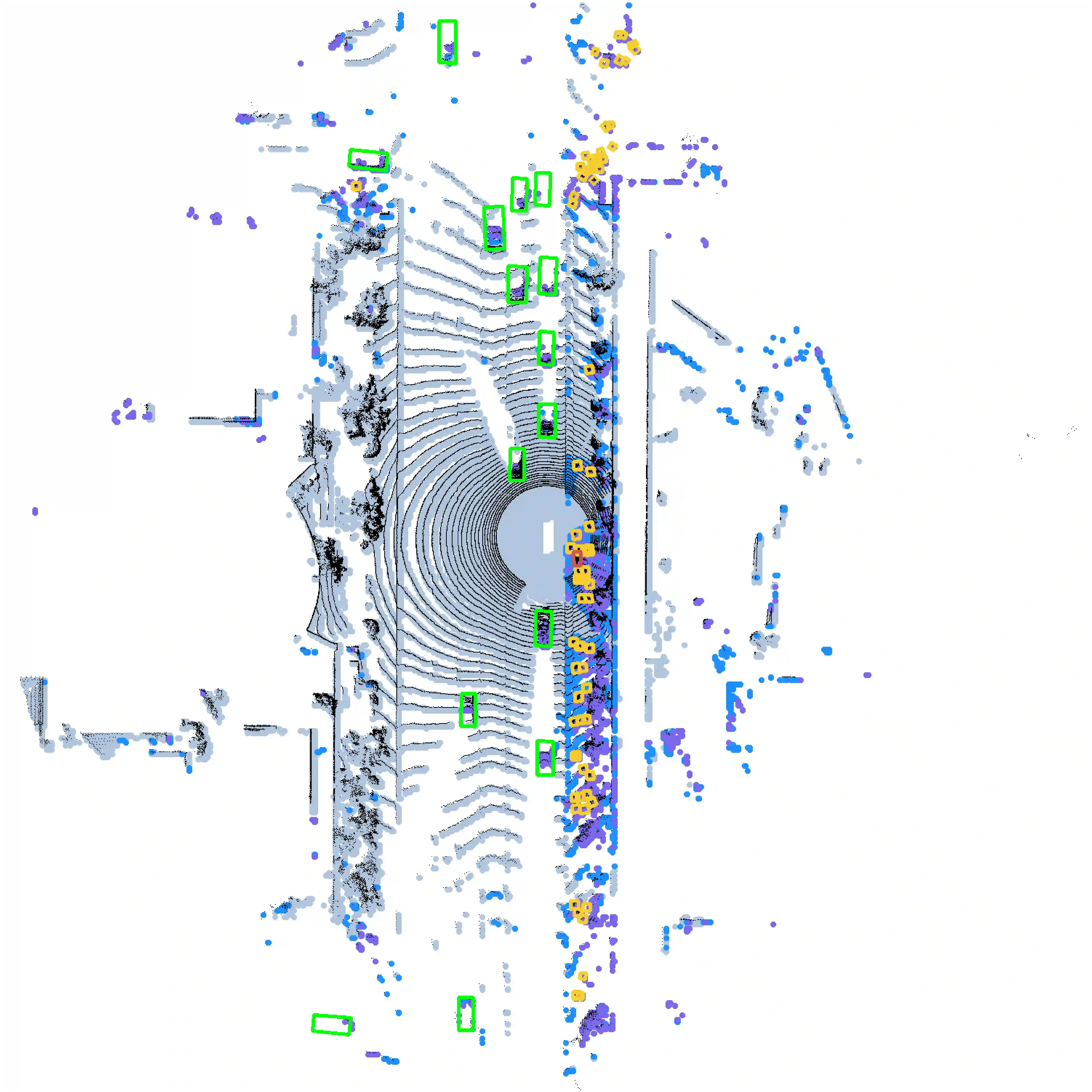
Balancing efficiency and accuracy is a long-standing problem for deploying deep learning models. The trade-off is even more important for real-time safety-critical systems like autonomous vehicles. In this paper, we propose an effective approach for accelerating transformer-based 3D object detectors by dynamically halting tokens at different layers depending on their contribution to the detection task. Although halting a token is a non-differentiable operation, our method allows for differentiable end-to-end learning by leveraging an equivalent differentiable forward-pass. Furthermore, our framework allows halted tokens to be reused to inform the model's predictions through a straightforward token recycling mechanism. Our method significantly improves the Pareto frontier of efficiency versus accuracy when compared with the existing approaches. By halting tokens and increasing model capacity, we are able to improve the baseline model's performance without increasing the model's latency on the Waymo Open Dataset.
翻译:暂无翻译