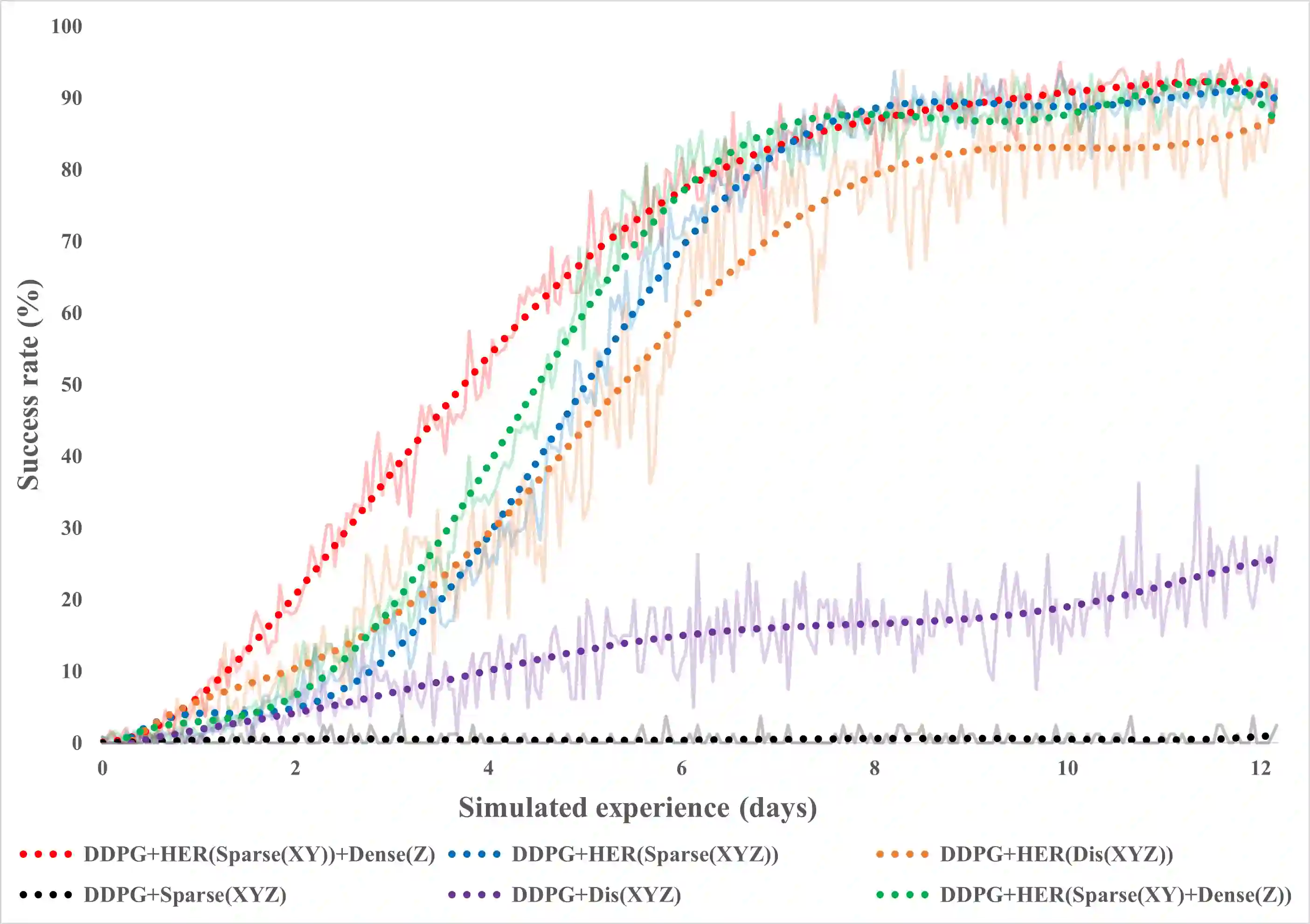
This paper describes a deep reinforcement learning (DRL) approach that won Phase 1 of the Real Robot Challenge (RRC) 2021, and then extends this method to a more difficult manipulation task. The RRC consisted of using a TriFinger robot to manipulate a cube along a specified positional trajectory, but with no requirement for the cube to have any specific orientation. We used a relatively simple reward function, a combination of goal-based sparse reward and distance reward, in conjunction with Hindsight Experience Replay (HER) to guide the learning of the DRL agent (Deep Deterministic Policy Gradient (DDPG)). Our approach allowed our agents to acquire dexterous robotic manipulation strategies in simulation. These strategies were then applied to the real robot and outperformed all other competition submissions, including those using more traditional robotic control techniques, in the final evaluation stage of the RRC. Here we extend this method, by modifying the task of Phase 1 of the RRC to require the robot to maintain the cube in a particular orientation, while the cube is moved along the required positional trajectory. The requirement to also orient the cube makes the agent unable to learn the task through blind exploration due to increased problem complexity. To circumvent this issue, we make novel use of a Knowledge Transfer (KT) technique that allows the strategies learned by the agent in the original task (which was agnostic to cube orientation) to be transferred to this task (where orientation matters). KT allowed the agent to learn and perform the extended task in the simulator, which improved the average positional deviation from 0.134 m to 0.02 m, and average orientation deviation from 142{\deg} to 76{\deg} during evaluation. This KT concept shows good generalisation properties and could be applied to any actor-critic learning algorithm.
翻译:本文描述一个深度强化学习( DRL) 方法, 它赢得了真实机器人挑战( RRC) 2021 (RRC) 第一阶段的第一阶段, 然后将这一方法推广到更困难的操作任务 。 RRC 包括使用 TriFinger 机器人来按照指定的位置轨迹操作立方体, 但是没有要求立方体有任何特定方向。 我们使用了一个相对简单的奖赏功能, 一种基于目标的微薄奖赏和距离奖赏的组合, 与 Hindsight 体验重现(HER) 一起, 来指导 DRL 代理( 深度确定性政策渐变 ) 的学习 。 我们的方法允许我们的代理方在模拟中获取 142 Exexteral 机器人操作策略。 这些策略随后被应用到真正的机器人, 但没有在 RRC 最终的评估阶段使用更传统的机械控制技术。 这里我们扩展了这个方法, 可以通过 RRC 第 1 阶段的任务来要求机器人在特定的方向上保持立方值, 而立方则按照要求的定位轨迹进行移动 。 。 同时, 使立方的立方使该代理服务器无法通过 复制任务 学习任务 。 ( 学习 K) 在初始任务中, 复制任务中, 学习 K 学习 K 将 K 复制到 复制任务中, 学习任务 学习 K 复制到 复制任务 任务 任务 复制到 复制到 K 任务 学习任务 任务 任务 。