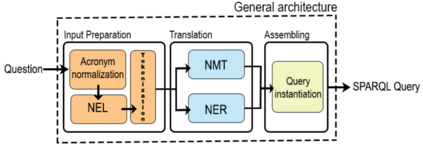
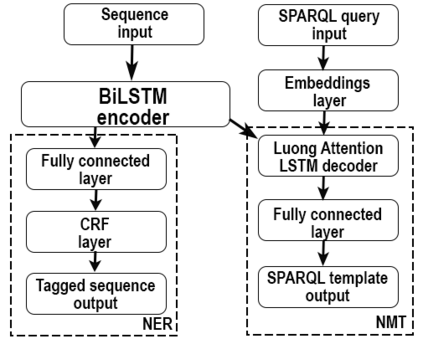
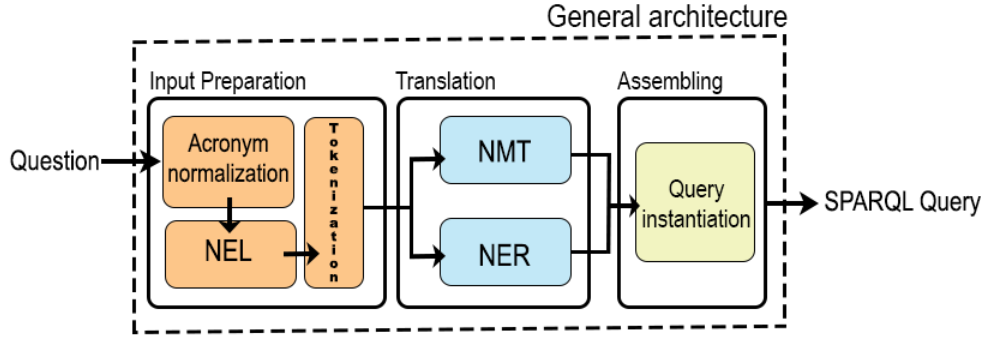
Accessing the large volumes of information available in public knowledge bases might be complicated for those users unfamiliar with the SPARQL query language. Automatic translation of questions posed in natural language in SPARQL has the potential of overcoming this problem. Existing systems based on neural-machine translation are very effective but easily fail in recognizing words that are Out Of the Vocabulary (OOV) of the training set. This is a serious issue while querying large ontologies. In this paper, we combine Named Entity Linking, Named Entity Recognition, and Neural Machine Translation to perform automatic translation of natural language questions into SPARQL queries. We demonstrate empirically that our approach is more effective and resilient to OOV words than existing approaches by running the experiments on Monument, QALD-9, and LC-QuAD v1, which are well-known datasets for Question Answering over DBpedia.
翻译:对于不熟悉SPARQL查询语言的用户来说,获取公共知识库中的大量信息可能比较复杂。 自动翻译SPARQL中以自然语言提出的问题有可能克服这一问题。 以神经机器翻译为基础的现有系统非常有效,但很容易无法识别培训成套词汇之外的单词。 这是一个严肃的问题,同时要询问大量主题。 在本文件中,我们将命名的实体链接、命名实体识别和神经机器翻译结合起来,以便自动将自然语言问题翻译为SPARQL查询。 我们从经验上证明,我们的方法比现有方法更有效、更能适应OOV语言,方法是在纪念碑、QALD-9和LC-QuAD v1上进行实验,这些实验是众所周知的DBpedia问题解答数据集。