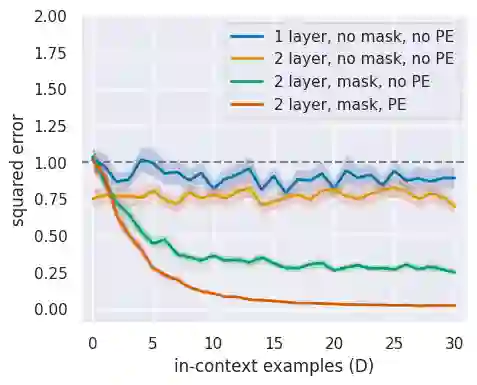
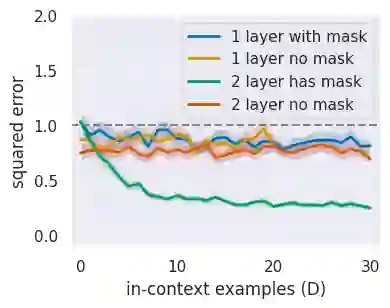
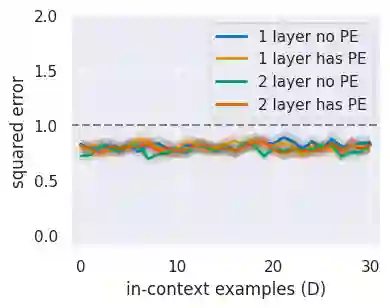
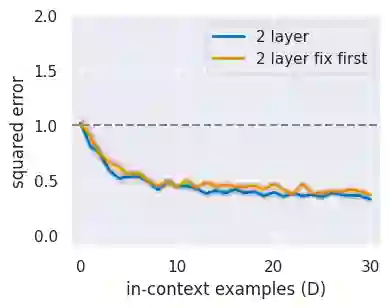
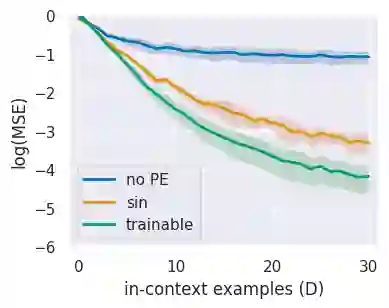
In practice, it is observed that transformer-based models can learn concepts in context in the inference stage. While existing literature, e.g., \citet{zhang2023trained,huang2023context}, provide theoretical explanations on this in-context learning ability, they assume the input $x_i$ and the output $y_i$ for each sample are embedded in the same token (i.e., structured data). However, in reality, they are presented in two tokens (i.e., unstructured data \cite{wibisono2023role}). In this case, this paper conducts experiments in linear regression tasks to study the benefits of the architecture of transformers and provides some corresponding theoretical intuitions to explain why the transformer can learn from unstructured data. We study the exact components in a transformer that facilitate the in-context learning. In particular, we observe that (1) a transformer with two layers of softmax (self-)attentions with look-ahead attention mask can learn from the prompt if $y_i$ is in the token next to $x_i$ for each example; (2) positional encoding can further improve the performance; and (3) multi-head attention with a high input embedding dimension has a better prediction performance than single-head attention.
翻译:暂无翻译