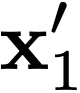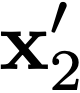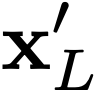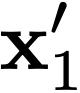In this paper, we propose a novel method to efficiently train a Generative Adversarial Network (GAN) on high dimensional samples. The key idea is to introduce a differentiable subsampling layer which appropriately reduces the dimensionality of intermediate feature maps in the generator during training. In general, generators require large memory and computational costs in the latter stages of the network as the feature maps become larger, though the latter stages have relatively fewer parameters than the earlier stages. It makes training large models for video generation difficult due to the limited computational resource. We solve this problem by introducing a method that gradually reduces the dimensionality of feature maps in the generator with multiple subsampling layers. We also propose a network (Temporal GAN v2) with such layers and perform video generation experiments. As a consequence, our model trained on the UCF101 dataset at $192 \times 192$ pixels achieves an Inception Score (IS) of 24.34, which shows a significant improvement over the previous state-of-the-art score of 14.56.
翻译:在本文中,我们提出一种新颖的方法,对高维样本进行基因反反转网络(GAN)的有效培训,关键的想法是引入一个可区分的子取样层,在培训期间适当减少发电机中中间地貌图的维度;一般而言,随着地貌图的扩大,发电机在网络后几个阶段需要大量的内存和计算费用,尽管后几个阶段的参数比早期的要少得多;由于计算资源有限,很难培训大型的视频生成模型;我们采用一种方法,逐渐减少多子取样层发电机中地貌图的维度,从而解决这个问题;我们还提议了一个具有这种层的网络(Terimoral GAN v2),并进行视频生成实验;结果,我们用UCFC101数据集培训的模型在192美元的24.34年达到摄取分(IS),该分数比以前14.56分的先进分有显著改进。