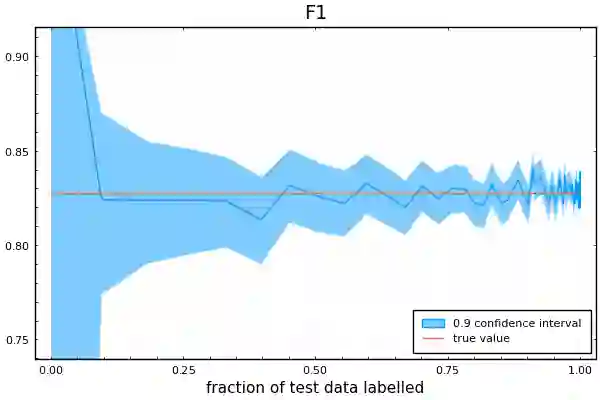
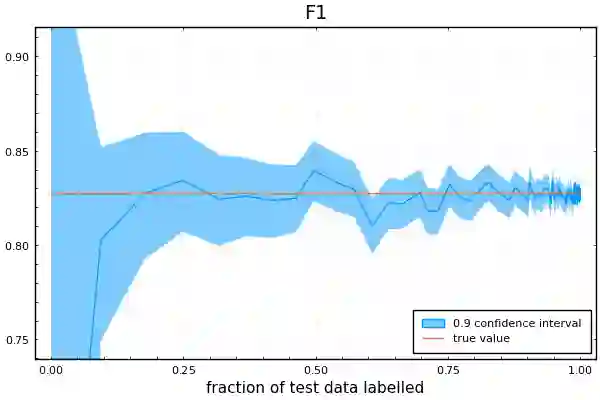
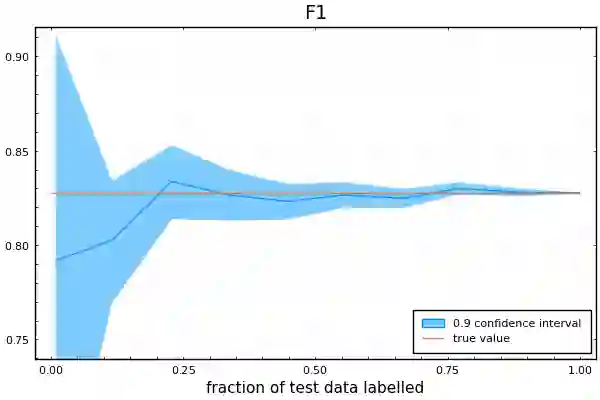
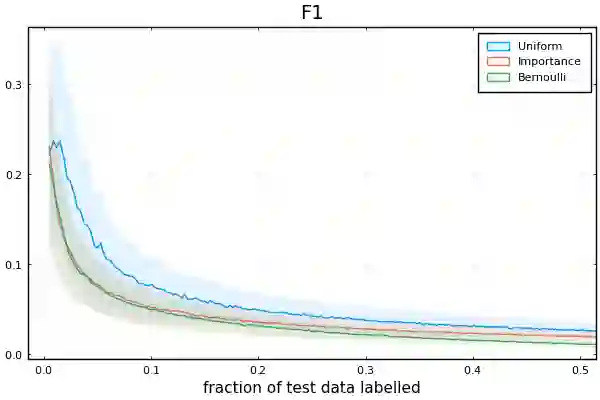
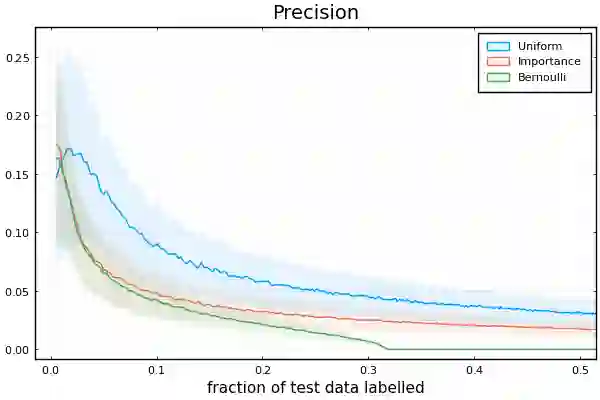
Labelling data is a major practical bottleneck in training and testing classifiers. Given a collection of unlabelled data points, we address how to select which subset to label to best estimate test metrics such as accuracy, $F_1$ score or micro/macro $F_1$. We consider two sampling based approaches, namely the well-known Importance Sampling and we introduce a novel application of Poisson Sampling. For both approaches we derive the minimal error sampling distributions and how to approximate and use them to form estimators and confidence intervals. We show that Poisson Sampling outperforms Importance Sampling both theoretically and experimentally.
翻译:标签数据是培训和测试分类系统的主要实际瓶颈。 在收集了未贴标签的数据点之后,我们讨论如何选择哪些子集作为最佳估计测试指标的标签,例如准确性、1美元分数或微观/宏观1美元分数。我们考虑两种基于抽样的方法,即众所周知的重要性抽样,我们引入了普瓦森抽样系统的新应用。对于这两种方法,我们得出最小的差错抽样分布,以及如何估计和使用它们来形成估测和信心间隔。我们显示,皮瓦森取样在理论上和实验上都超越了重要性抽样。