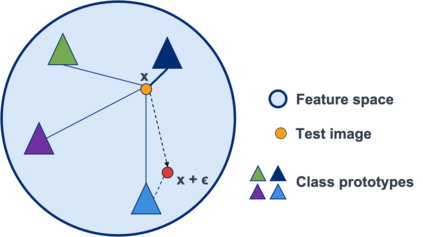
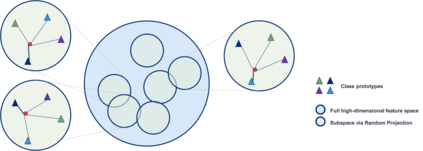
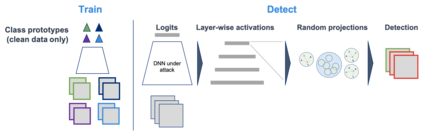
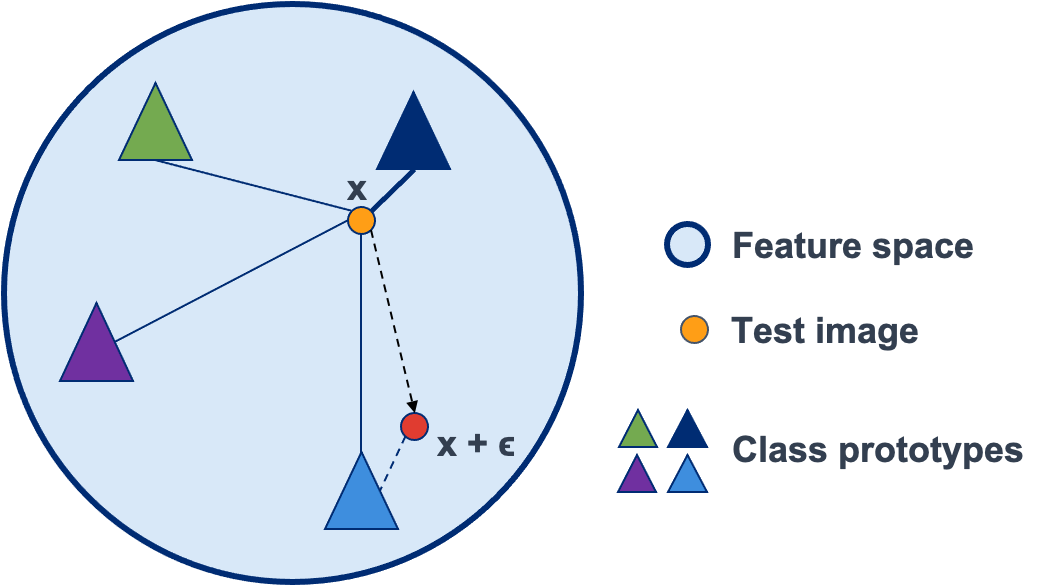
Whilst adversarial attack detection has received considerable attention, it remains a fundamentally challenging problem from two perspectives. First, while threat models can be well-defined, attacker strategies may still vary widely within those constraints. Therefore, detection should be considered as an open-set problem, standing in contrast to most current detection strategies. These methods take a closed-set view and train binary detectors, thus biasing detection toward attacks seen during detector training. Second, information is limited at test time and confounded by nuisance factors including the label and underlying content of the image. Many of the current high-performing techniques use training sets for dealing with some of these issues, but can be limited by the overall size and diversity of those sets during the detection step. We address these challenges via a novel strategy based on random subspace analysis. We present a technique that makes use of special properties of random projections, whereby we can characterize the behavior of clean and adversarial examples across a diverse set of subspaces. We then leverage the self-consistency (or inconsistency) of model activations to discern clean from adversarial examples. Performance evaluation demonstrates that our technique outperforms ($>0.92$ AUC) competing state of the art (SOTA) attack strategies, while remaining truly agnostic to the attack method itself. It also requires significantly less training data, composed only of clean examples, when compared to competing SOTA methods, which achieve only chance performance, when evaluated in a more rigorous testing scenario.
翻译:虽然对抗性攻击探测受到相当重视,但从两个角度来说,它仍然是一个具有根本挑战性的问题。第一,虽然威胁模型可以明确界定,但攻击者战略在这些限制范围内可能仍然有很大差异。因此,应当将探测视为一个开放的难题,与目前大多数探测战略形成对照。这些方法采用封闭的视图,训练二进制探测器,从而将探测结果偏向于探测训练期间所看到的攻击;第二,在试验时间,信息有限,而且由于包括标签和图像基本内容在内的模糊因素而令人困惑。许多目前的高性能技术利用训练来处理其中一些问题,但由于探测步骤期间这些装置的总体规模和多样性而可能受到限制。我们通过随机的子空间分析的新战略来应对这些挑战。我们采用一种技术,利用随机预测的特殊特性,从而可以辨别在各种子空间中出现的清洁和对抗性例子的行为。我们随后利用模型激活的自相协调(或不一致)来辨别一些敌对性实例。许多高性技术使用训练来对付这些问题,但由于探测步骤的总体规模和多样性而受到限制。我们通过一种新的战略来应付这些挑战。我们的方法,我们采用随机性战略是比较不那么的测试方法。