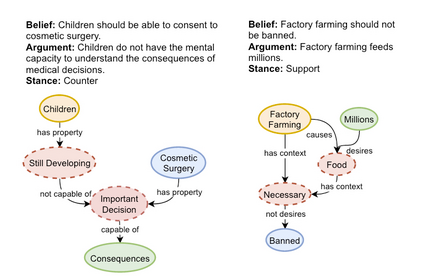
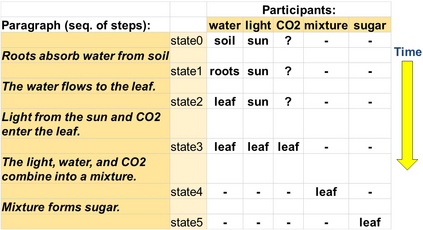
We address the general task of structured commonsense reasoning: given a natural language input, the goal is to generate a graph such as an event -- or a reasoning-graph. To employ large language models (LMs) for this task, existing approaches ``serialize'' the output graph as a flat list of nodes and edges. Although feasible, these serialized graphs strongly deviate from the natural language corpora that LMs were pre-trained on, hindering LMs from generating them correctly. In this paper, we show that when we instead frame structured commonsense reasoning tasks as code generation tasks, pre-trained LMs of code are better structured commonsense reasoners than LMs of natural language, even when the downstream task does not involve source code at all. We demonstrate our approach across three diverse structured commonsense reasoning tasks. In all these natural language tasks, we show that using our approach, a code generation LM (CODEX) outperforms natural-LMs that are fine-tuned on the target task (e.g., T5) and other strong LMs such as GPT-3 in the few-shot setting.
翻译:我们处理的是结构化常识推理的一般任务:根据自然语言投入,目标是生成一个图表,如事件或推理等。为了使用大型语言模型(LMs)来完成这项任务,现有方法将输出图“序列化”成一个节点和边缘的平板列表。虽然可行,但这些序列化图与LMs预先培训过的自然语言团团团有很大不同,阻碍了LMs正确生成。在本文中,我们表明,当我们把结构化常识推理任务作为代码生成任务时,预先培训的代码团团比自然语言团团团(LMs)更结构化的常识辨识力强,即使下游任务根本不涉及源码。我们展示了我们的方法有三种不同的结构化共性推理任务。在所有这些自然语言任务中,我们显示,使用我们的方法,代号LM(CODEX)的代号(CODEX)优于目标任务(例如T5)和其他强力的LMs,例如低光谱制成的GPT-3等自然-LMs。