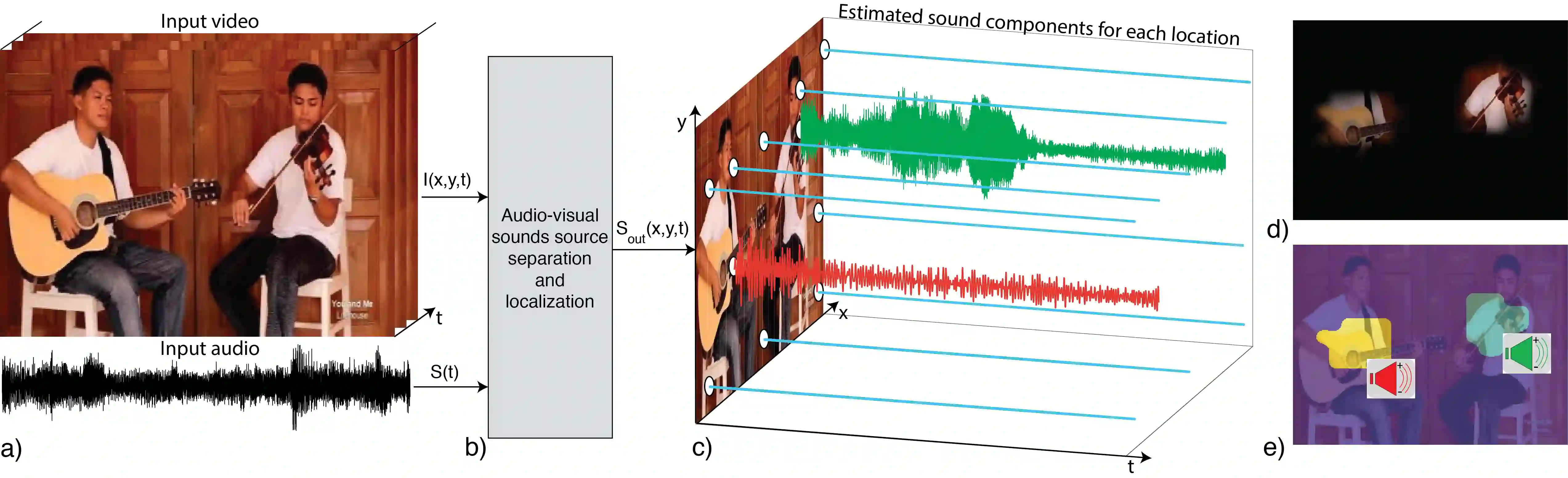
We introduce PixelPlayer, a system that, by leveraging large amounts of unlabeled videos, learns to locate image regions which produce sounds and separate the input sounds into a set of components that represents the sound from each pixel. Our approach capitalizes on the natural synchronization of the visual and audio modalities to learn models that jointly parse sounds and images, without requiring additional manual supervision. Experimental results on a newly collected MUSIC dataset show that our proposed Mix-and-Separate framework outperforms several baselines on source separation. Qualitative results suggest our model learns to ground sounds in vision, enabling applications such as independently adjusting the volume of sound sources.
翻译:我们引入了像素Player, 该系统通过利用大量未贴标签的视频, 学会定位生成声音的图像区域, 并将输入的声音分离成代表每个像素声音的一组组件。 我们的方法利用视觉和音频模式的自然同步性来学习联合分析声音和图像的模型, 而不需要额外的人工监督。 新收集的 Mix- Sparate 数据集的实验结果显示, 我们提议的 Mix- sparate 框架在源分离上优于几个基线。 定性结果显示, 我们的模型学会将声音定位在视觉中, 使应用能够独立调整声音源的数量等。