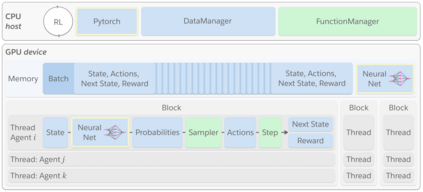
Deep reinforcement learning (RL) is a powerful framework to train decision-making models in complex dynamical environments. However, RL can be slow as it learns through repeated interaction with a simulation of the environment. Accelerating RL requires both algorithmic and engineering innovations. In particular, there are key systems engineering bottlenecks when using RL in complex environments that feature multiple agents or high-dimensional state, observation, or action spaces, for example. We present WarpDrive, a flexible, lightweight, and easy-to-use open-source RL framework that implements end-to-end multi-agent RL on a single GPU (Graphics Processing Unit), building on PyCUDA and PyTorch. Using the extreme parallelization capability of GPUs, WarpDrive enables orders-of-magnitude faster RL compared to common implementations that blend CPU simulations and GPU models. Our design runs simulations and the agents in each simulation in parallel. It eliminates data copying between CPU and GPU. It also uses a single simulation data store on the GPU that is safely updated in-place. Together, this allows the user to run thousands of concurrent multi-agent simulations and train on extremely large batches of experience. For example, WarpDrive yields 2.9 million environment steps/second with 2000 environments and 1000 agents (at least 100x higher throughput compared to a CPU implementation) in a benchmark Tag simulation. WarpDrive provides a lightweight Python interface and environment wrappers to simplify usage and promote flexibility and extensions. As such, WarpDrive provides a framework for building high-throughput RL systems.
翻译:深度增强学习(RL)是复杂动态环境中培训决策模型的强大框架。然而,RL在通过反复与环境模拟互动学习的过程中速度可能很慢。加速RL需要算法和工程创新。特别是,在复杂环境中使用RL存在关键的系统工程瓶颈,这些环境具有多重剂或高维状态、观测或行动空间等特征。我们提出了WarpDrive,这是一个灵活、轻量和易于使用的开放源代码RL框架,用于在单一GPU(Graphics处理股)上,在PyCUDA和PyTorch上进行简化到终端多剂 RLL。利用GL的极端平行能力,WarpD在使用RL时,与将CP的模拟模型和GP模型混合在一起,我们的设计运行模拟器和每次模拟的代理器。它消除了CPU和GPU之间的数据复制。它还在GPU(GPU)上使用一个单一的模拟数据存储存储存储器数据存储器存储器,并在2000年的Prillex运行一个极高水平的Pral环境上,使这个用户能够通过一个快速运行一个模拟环境,在2000年的Pral。