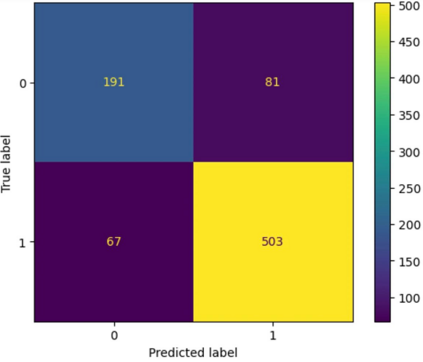
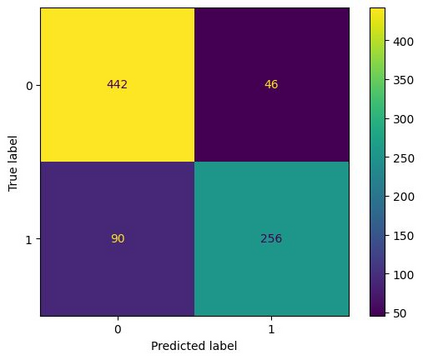
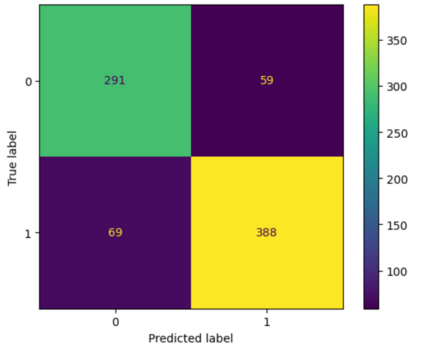
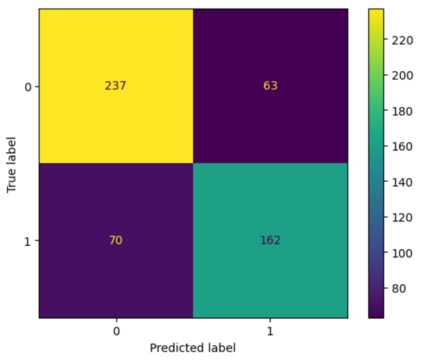
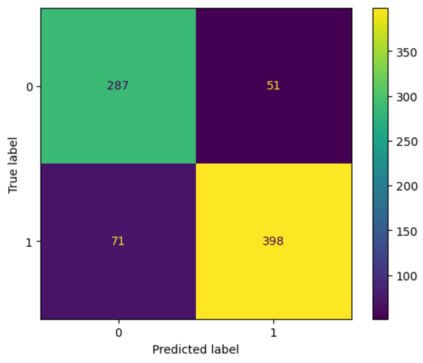
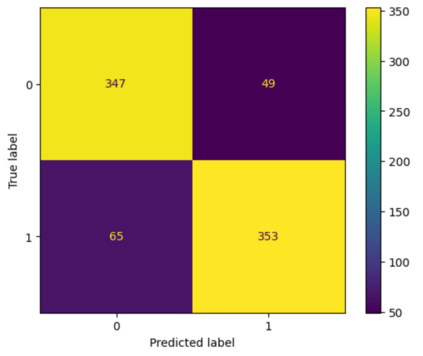
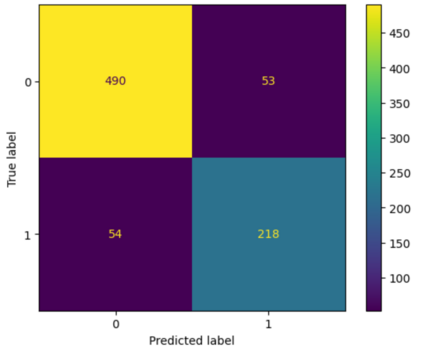
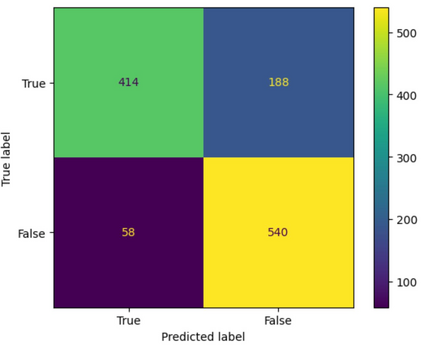
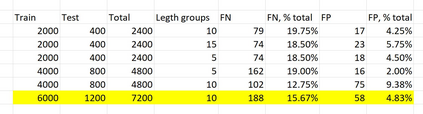
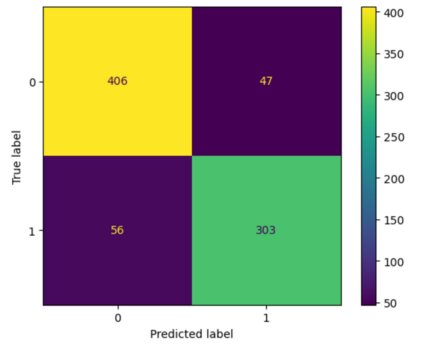
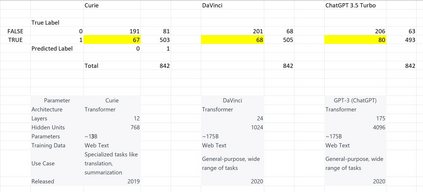
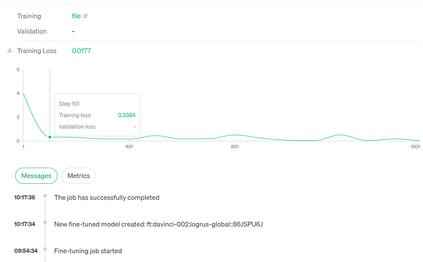
Translation Quality Evaluation (TQE) is an essential step of the modern translation production process. TQE is critical in assessing both machine translation (MT) and human translation (HT) quality without reference translations. The ability to evaluate or even simply estimate the quality of translation automatically may open significant efficiency gains through process optimisation. This work examines whether the state-of-the-art large language models (LLMs) can be used for this purpose. We take OpenAI models as the best state-of-the-art technology and approach TQE as a binary classification task. On eight language pairs including English to Italian, German, French, Japanese, Dutch, Portuguese, Turkish, and Chinese, our experimental results show that fine-tuned gpt3.5 can demonstrate good performance on translation quality prediction tasks, i.e. whether the translation needs to be edited. Another finding is that simply increasing the sizes of LLMs does not lead to apparent better performances on this task by comparing the performance of three different versions of OpenAI models: curie, davinci, and gpt3.5 with 13B, 175B, and 175B parameters, respectively.
翻译:暂无翻译