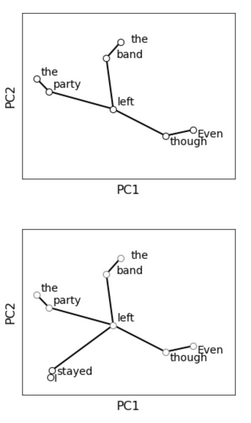
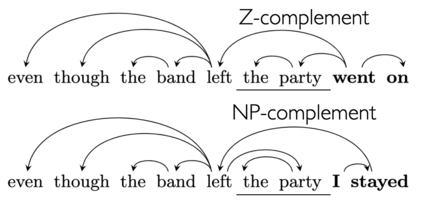
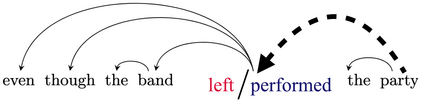
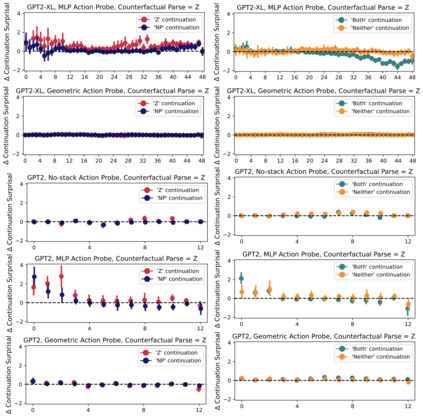
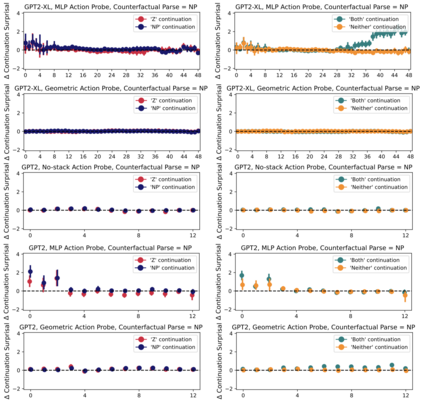
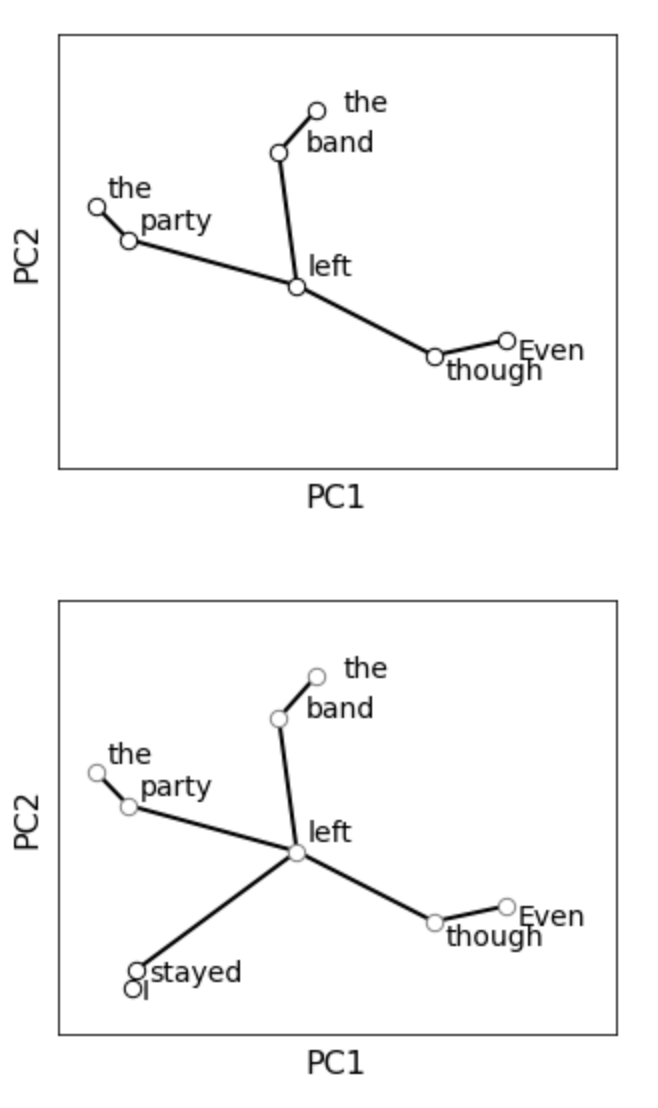
Next-word predictions from autoregressive neural language models show remarkable sensitivity to syntax. This work evaluates the extent to which this behavior arises as a result of a learned ability to maintain implicit representations of incremental syntactic structures. We extend work in syntactic probing to the incremental setting and present several probes for extracting incomplete syntactic structure (operationalized through parse states from a stack-based parser) from autoregressive language models. We find that our probes can be used to predict model preferences on ambiguous sentence prefixes and causally intervene on model representations and steer model behavior. This suggests implicit incremental syntactic inferences underlie next-word predictions in autoregressive neural language models.
翻译:自动递减神经语言模型的下个字预测显示了对语法的显著敏感性。 这项工作评估了由于学习了维持递增合成结构的隐含表现的能力而产生这种行为的程度。 我们把合成检验工作扩大到递增设置,并提出了从自动递减语言模型中提取不完整的合成结构( 通过堆叠式剖析状态操作)的若干探测器。 我们发现,我们的探测器可以用来预测模范偏好模棱两可的句前缀,并对模型显示和引导模型行为进行因果干预。 这表明自动递减神经语言模型的下一个词预测基于隐含的递增综合推断。