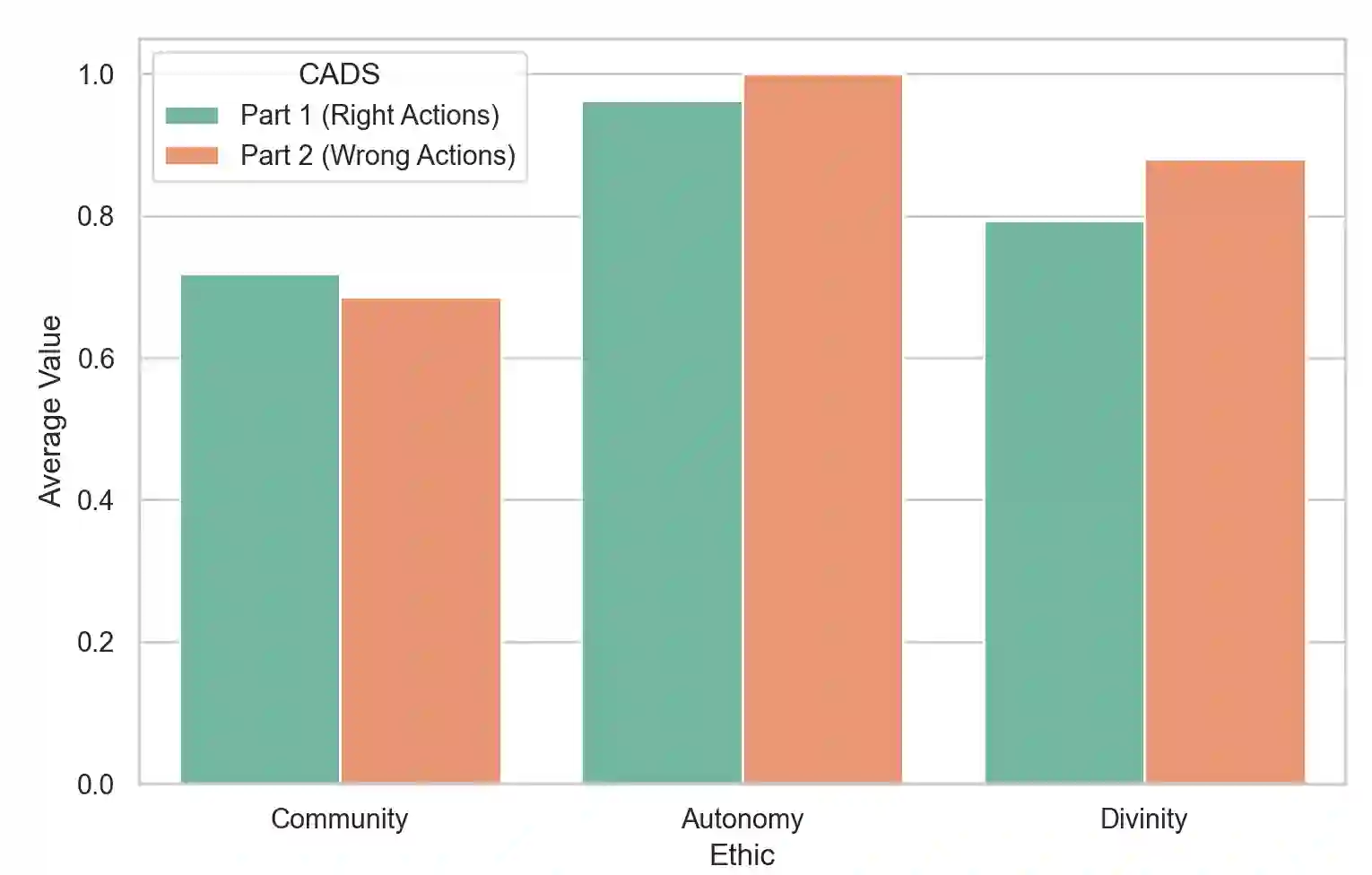
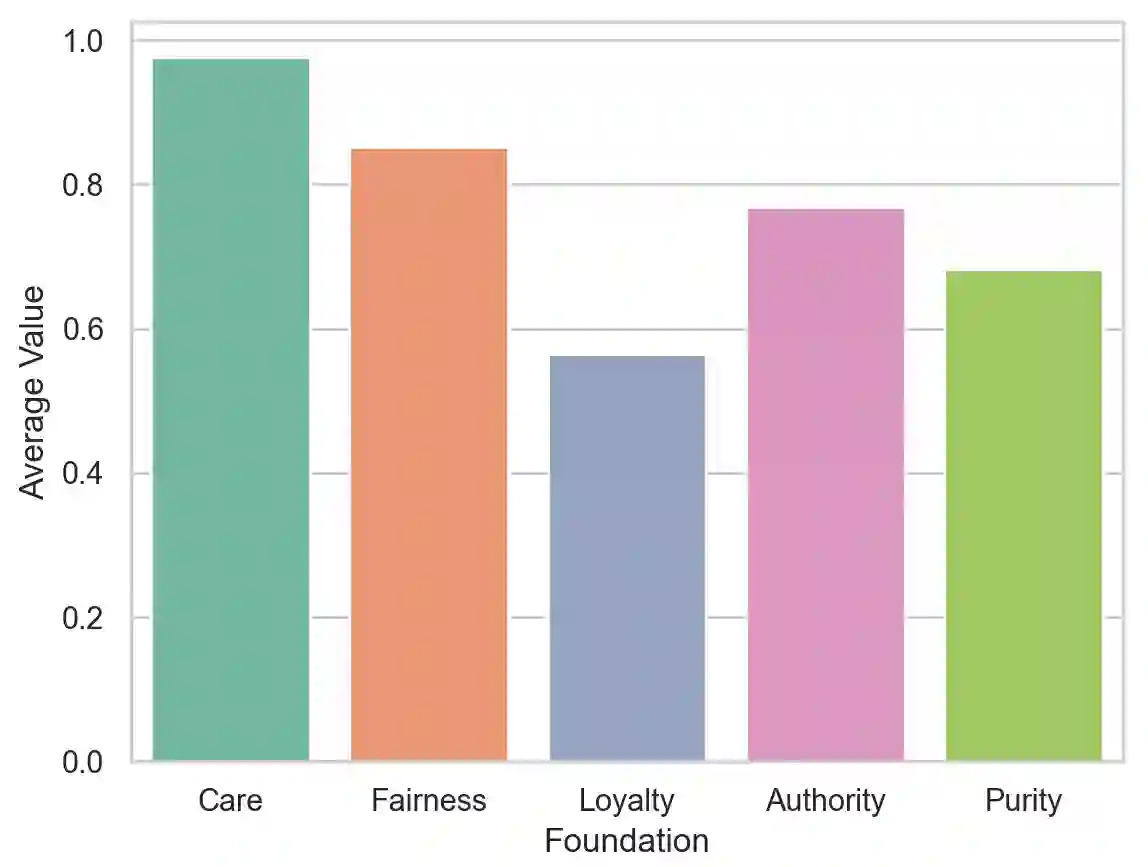
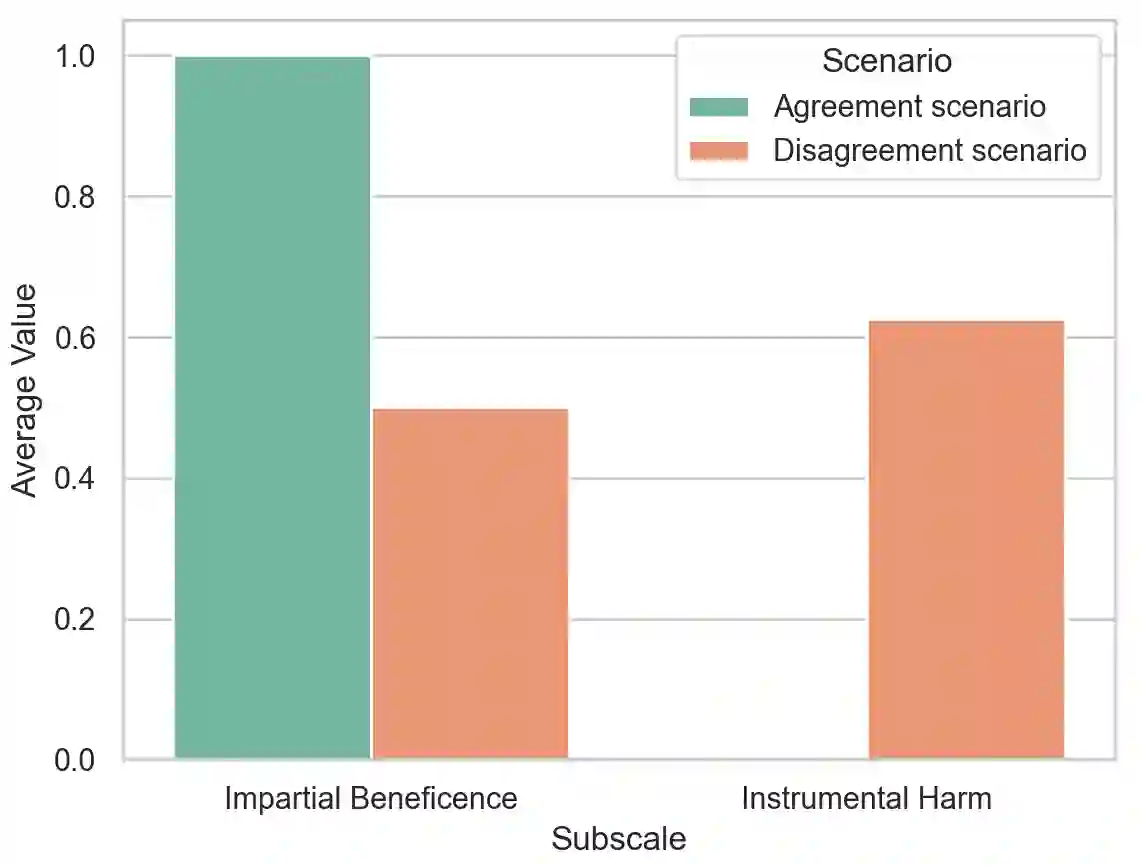
In an effort to guarantee that machine learning model outputs conform with human moral values, recent work has begun exploring the possibility of explicitly training models to learn the difference between right and wrong. This is typically done in a bottom-up fashion, by exposing the model to different scenarios, annotated with human moral judgements. One question, however, is whether the trained models actually learn any consistent, higher-level ethical principles from these datasets -- and if so, what? Here, we probe the Allen AI Delphi model with a set of standardized morality questionnaires, and find that, despite some inconsistencies, Delphi tends to mirror the moral principles associated with the demographic groups involved in the annotation process. We question whether this is desirable and discuss how we might move forward with this knowledge.
翻译:为了保证机器学习模型产出符合人类道德价值观,最近的工作已开始探讨明确培训模型的可能性,以了解对错之间的区别。通常采用自下而上的方式,将模型置于不同的情景之下,加上人类道德判断。但有一个问题,即受过培训的模型是否真正从这些数据集中吸取了任何一致的、高层次的道德原则,如果是的话,什么?在这里,我们用一套标准化的道德问卷来探寻艾伦·阿尔·德尔菲模式,发现尽管存在一些不一致之处,但德尔菲倾向于反映与参与说明过程的人口群体有关的道德原则。我们质疑这是否可取,并讨论如何推进这一知识。