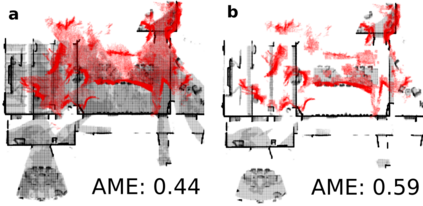
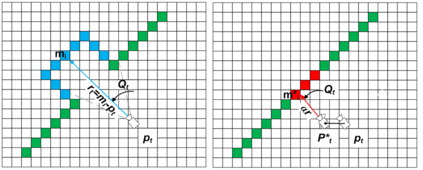
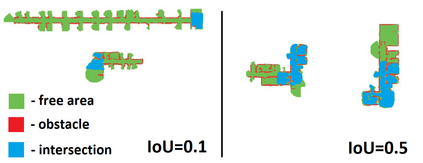
Running numerous experiments in simulation is a necessary step before deploying a control system on a real robot. In this paper we introduce a novel benchmark that is aimed at quantitatively evaluating the quality of vision-based simultaneous localization and mapping (vSLAM) and map merging algorithms. The benchmark consists of both a dataset and a set of tools for automatic evaluation. The dataset is photo-realistic and provides both the localization and the map ground truth data. This makes it possible to evaluate not only the localization part of the SLAM pipeline but the mapping part as well. To compare the vSLAM-built maps and the ground-truth ones we introduce a novel way to find correspondences between them that takes the SLAM context into account (as opposed to other approaches like nearest neighbors). The benchmark is ROS-compatable and is open-sourced to the community. The data and the code are available at: \texttt{github.com/CnnDepth/MAOMaps}.
翻译:在模拟中进行无数的实验是部署真正机器人控制系统的必要步骤。 在本文中, 我们引入了一个新的基准, 目的是从数量上评估基于视觉的同步本地化和绘图( vSLAM) 和地图合并算法的质量。 基准由数据集和一套自动评估工具组成。 数据集具有摄影现实性, 提供了本地化和地图地面真实数据。 这样不仅能够评估 SLAM 管道的本地化部分, 还可以评估绘图部分。 要比较 vSLAM 建造的地图和地面真象, 我们引入了一种新颖的方法, 来查找它们之间考虑到SLAM 上下文的对应信息( 而不是其他类似近邻的方法 ) 。 基准是 ROS 兼容, 并且向社区开放。 数据和代码可以在 \ texttt{github.com/ CnnDepeh/MAOMaps} 。