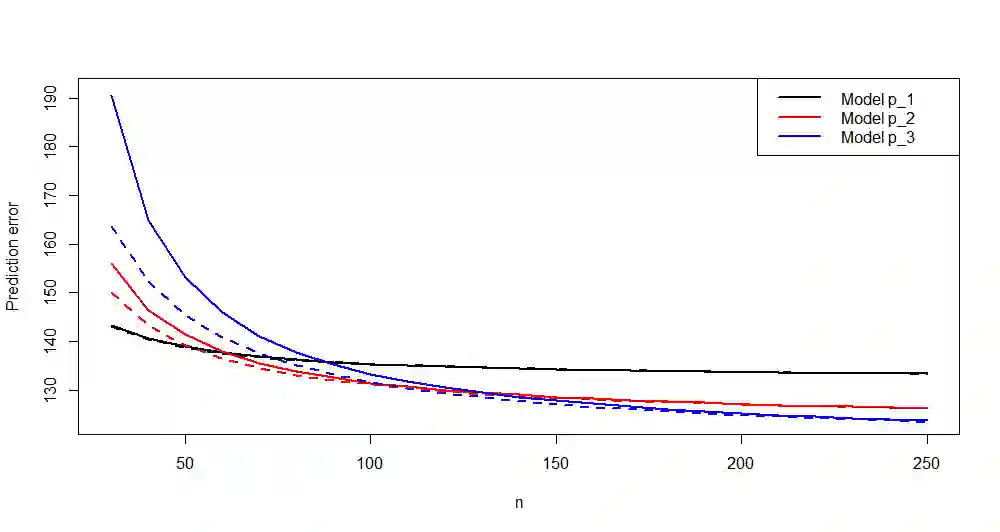
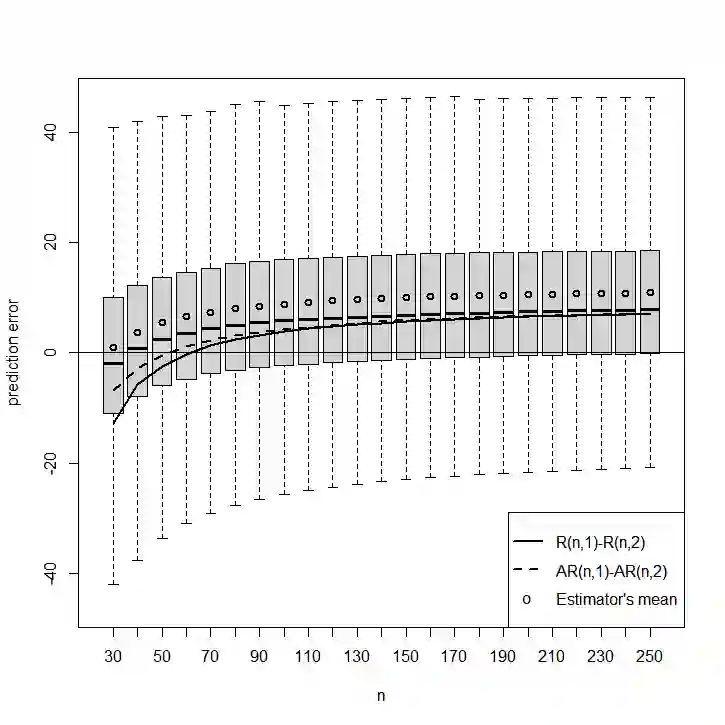
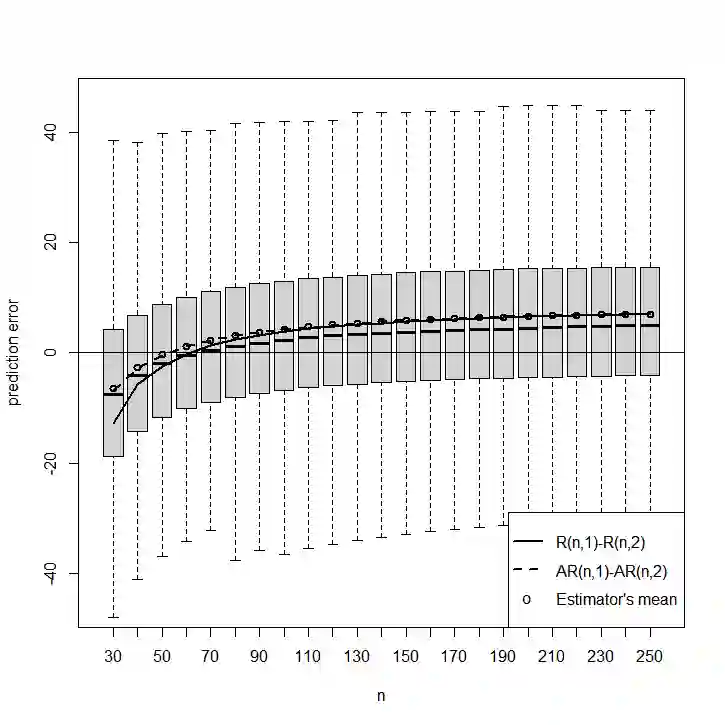
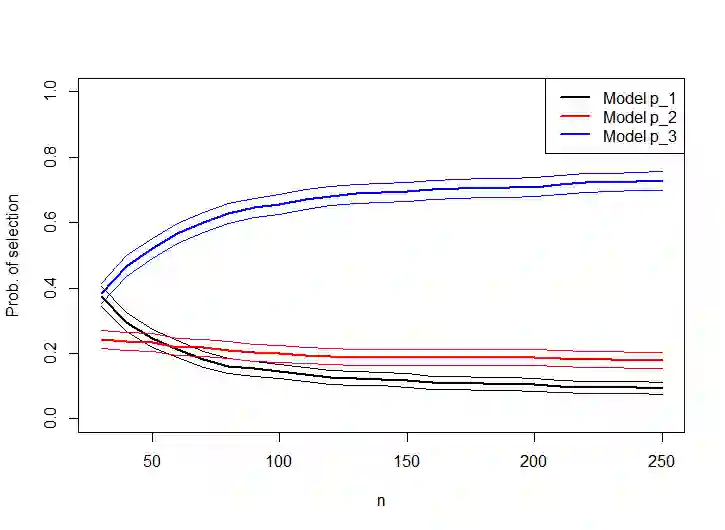
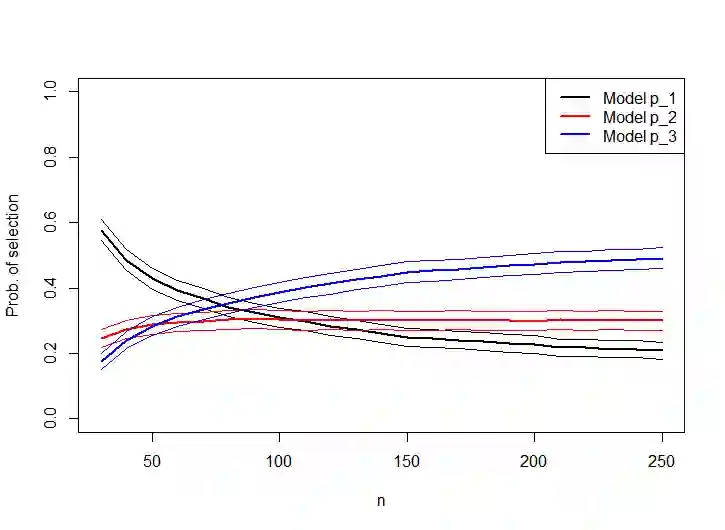
Given a regression dataset of size $n$, most of the classical model selection literature treats the problem of selecting a subset of covariates to be used for prediction of future responses. In this paper we assume that a sample of $\cal J$ regression datasets of different sizes from a population of datasets having the same set of covariates and responses is observed. The goal is to select, for each $n$, a single subset of covariates to be used for prediction of future responses for any dataset of size $n$ from the population (which may or may not be in the sample of datasets). The regression coefficients used in the prediction are estimated using the $n$ observations consisting of covariates and responses in the sample for which prediction of future responses is to be done, and thus they differ across different samples. For example, if the response is a diagnosis, and the covariates are medical background variables and measurements, the goal is to select a standard set of measurements for different clinics, say, where each clinic may estimate and use its own coefficients for prediction (depending on local conditions, prevalence, etc.). The selected subset naturally depends on the sample size $n$, with a larger sample size allowing a more elaborate model. Since we consider prediction for any (or a randomly chosen) dataset in the population, it is natural to consider random covariates. If the population consists of datasets that are similar, our approach amounts to borrowing information, leading to a subset selection that is efficient for prediction. On the other hand, if the datasets are dissimilar, then our goal is to find a "compromise" subset of covariates for the different regressions.
翻译:鉴于一个大小为$美元的回归数据集,大多数古典模式选择文献都处理选择一组用于预测未来答复的共变数的问题。在本文中,我们假设,从一组具有相同共变数和答复的数据集中,将观察到不同规模的美元/cal J$回归数据集样本,从一组具有不同规模的数据集中将观察到不同规模的美元/cal J$回归数据集,目标是为每一组美元/美元/方差数的人群选择一组共变数,用于预测未来对某个规模为美元/方差数的数据集(这些数据集可能或可能不在数据集的样本中)。预测中使用的回归系数是使用由对未来答复作出预测的样本中的共变数和答复组成的美元(因此,它们在不同样本中,如果答复是一种诊断,而共变差数是医疗背景变量和测量,那么目标是为不同的诊所选择一套标准测量方法,如果每个诊所可以估算并使用自己的系数进行预测(取决于当地条件、普遍率、等等 ) 预测所使用的回归系数是美元/ral 值的观察,因此,所选择的子数是更精确的样本中, 。由于选择的数据是比重的大小(我们所选择的比值, ) 将自然数据是比重的比重的大小。 。 。自然数据是比重的比重的比重 。 。 。 。 。 。 。 。 。 。 。 。 任何子值 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。