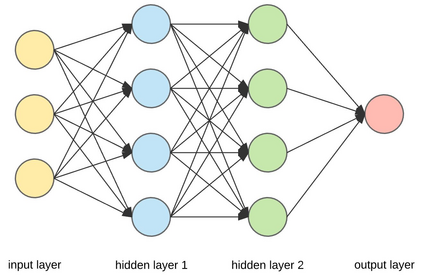
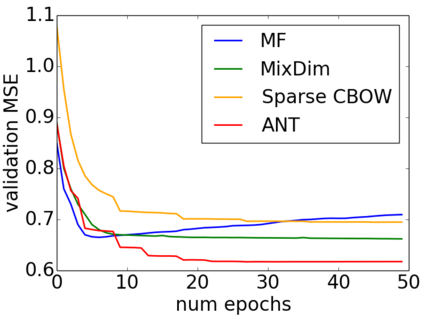
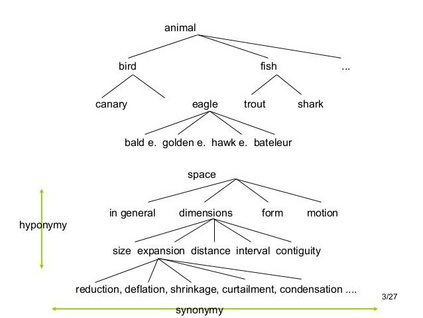
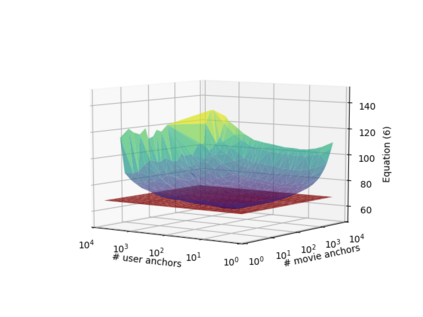
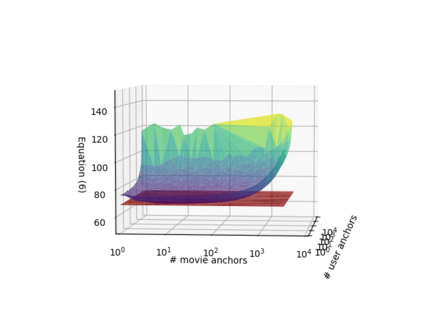
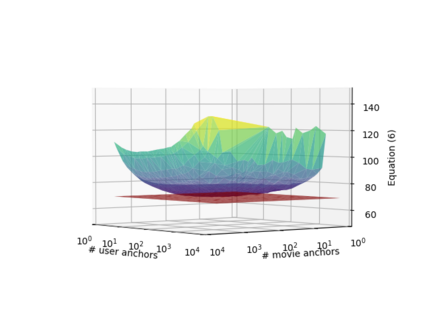
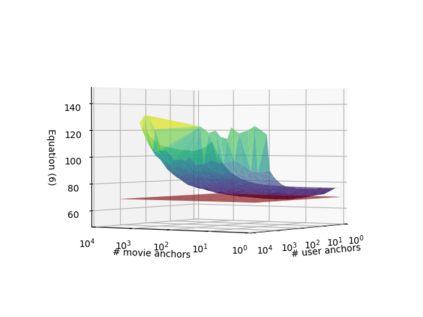
Learning continuous representations of discrete objects such as text, users, movies, and URLs lies at the heart of many applications including language and user modeling. When using discrete objects as input to neural networks, we often ignore the underlying structures (e.g. natural groupings and similarities) and embed the objects independently into individual vectors. As a result, existing methods do not scale to large vocabulary sizes. In this paper, we design a simple and efficient embedding algorithm that learns a small set of anchor embeddings and a sparse transformation matrix. We call our method Anchor & Transform (ANT) as the embeddings of discrete objects are a sparse linear combination of the anchors, weighted according to the transformation matrix. ANT is scalable, flexible, and end-to-end trainable. We further provide a statistical interpretation of our algorithm as a Bayesian nonparametric prior for embeddings that encourages sparsity and leverages natural groupings among objects. By deriving an approximate inference algorithm based on Small Variance Asymptotics, we obtain a natural extension that automatically learns the optimal number of anchors instead of having to tune it as a hyperparameter. On text classification, language modeling, and movie recommendation benchmarks, we show that ANT is particularly suitable for large vocabulary sizes and demonstrates stronger performance with fewer parameters (up to 40x compression) as compared to existing compression baselines.
翻译:文本、 用户、 电影 和 URL 等离散对象的连续学习表现是许多应用程序的核心, 包括语言和用户模型。 当使用离散对象作为神经网络的输入器时, 我们常常忽略基本结构( 如自然组合和相似性), 并将对象独立嵌入单个矢量。 因此, 现有方法不比大词汇大小。 在本文中, 我们设计一个简单有效的嵌入算法, 学习小套嵌套和稀薄的变换矩阵。 我们称我们的方法“ 锁定和变换( ANT) ”, 因为离散对象的嵌入是按变换矩阵加权的细小线性组合。 NAT 是可伸缩的, 灵活和端到端到端到矢量的向量。 我们进一步提供我们算法的统计解释, 因为它是一个不比大的词汇大小。 通过基于小差异 Asty 的大致推导算法, 我们获得了自然扩展, 可以自动学习最优化的锚值组合组合组合组合, 而不是更精确的缩的缩缩缩的缩缩缩缩缩缩的缩缩的缩缩缩缩缩图 。