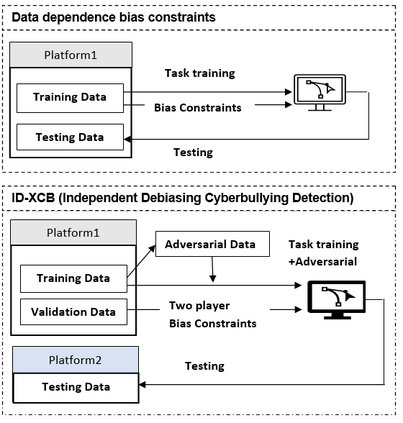
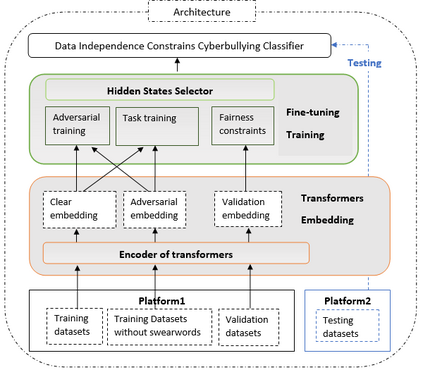
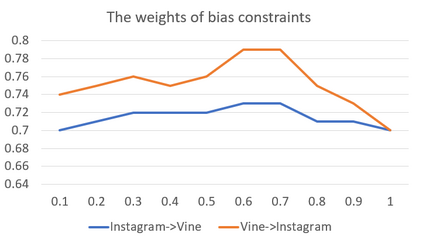
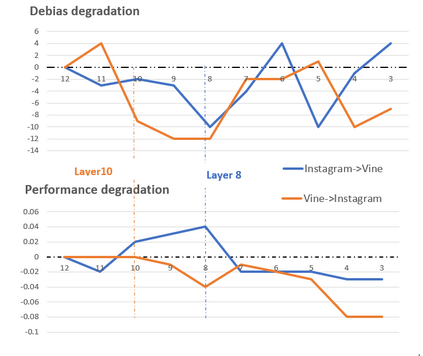
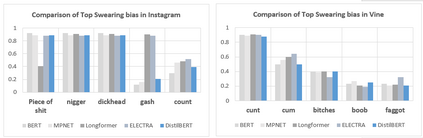
Swear words are a common proxy to collect datasets with cyberbullying incidents. Our focus is on measuring and mitigating biases derived from spurious associations between swear words and incidents occurring as a result of such data collection strategies. After demonstrating and quantifying these biases, we introduce ID-XCB, the first data-independent debiasing technique that combines adversarial training, bias constraints and debias fine-tuning approach aimed at alleviating model attention to bias-inducing words without impacting overall model performance. We explore ID-XCB on two popular session-based cyberbullying datasets along with comprehensive ablation and generalisation studies. We show that ID-XCB learns robust cyberbullying detection capabilities while mitigating biases, outperforming state-of-the-art debiasing methods in both performance and bias mitigation. Our quantitative and qualitative analyses demonstrate its generalisability to unseen data.
翻译:暂无翻译