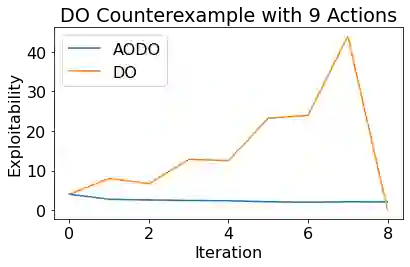
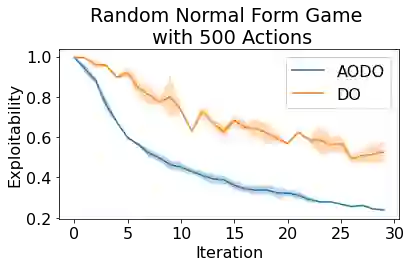
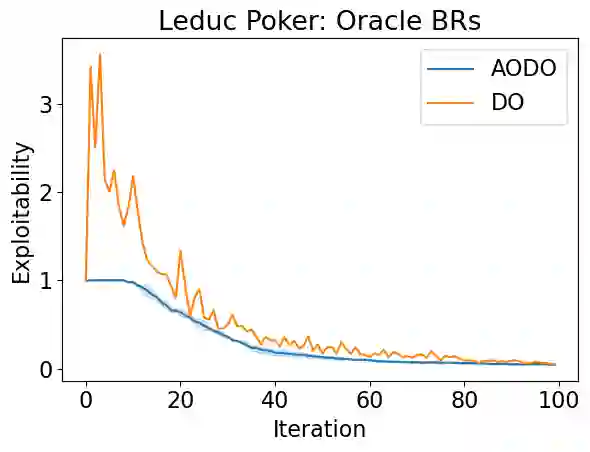
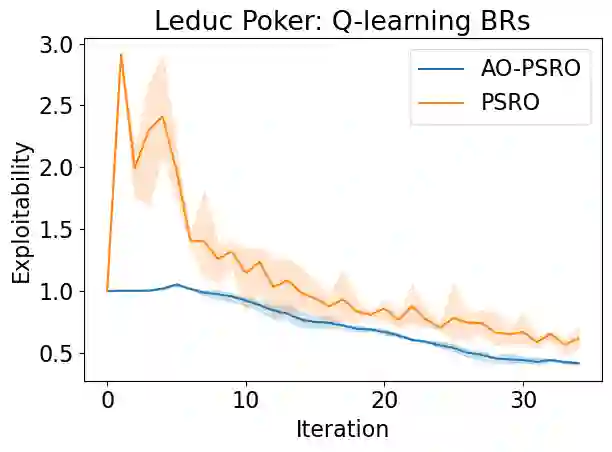
Policy Space Response Oracles (PSRO) is a multi-agent reinforcement learning algorithm for games that can handle continuous actions and has empirically found approximate Nash equilibria in large games. PSRO is based on the tabular Double Oracle (DO) method, an algorithm that is guaranteed to converge to a Nash equilibrium, but may increase exploitability from one iteration to the next. We propose Anytime Optimal Double Oracle (AODO), a tabular double oracle algorithm for 2-player zero-sum games that is guaranteed to converge to a Nash equilibrium while decreasing exploitability from iteration to iteration. Unlike DO, in which the meta-strategy is based on the restricted game formed by each player's strategy sets, AODO finds the meta-strategy for each player that minimizes its exploitability against any policy in the full, unrestricted game. We also propose a method of finding this meta-strategy via a no-regret algorithm updated against a continually-trained best response, called RM-BR DO. Finally, we propose Anytime Optimal PSRO, a version of AODO that calculates best responses via reinforcement learning. In experiments on Leduc poker and random normal form games, we show that our methods achieve far lower exploitability than DO and PSRO and never increase exploitability.
翻译:空间政策反应甲骨文(PSRO)是针对游戏的一种多试剂强化学习算法,可以处理连续的行动,并且从经验中发现在大型游戏中近似Nash 平衡。 PSRO基于表格式双甲骨文(DO)方法,该算法保证会与纳什均衡趋同,但有可能增加利用性,从一个迭代到另一个。我们提议了一种表格式的双甲骨文(AODO)算法,用于双人零和双人游戏,保证会与纳什平衡趋同,同时会降低从迭代到迭代的可利用性。与DOO不同,在DO(DO)中,该元战略是基于每个玩家战略所形成的有限游戏,该算法保证会与任何完全、无限制的游戏相比,最大限度地减少其利用性。我们还提议了一种方法,通过一个不重复式的算法,通过持续训练的最佳反应,称为RM-BDO(DO),我们提议任何时间式的PSRO(PRO)的元战略是以每个玩法为基础的游戏为基础。AODO(ADOADO),一个在最高级的实验中不进行最佳的学习方法中,不增加利用性实验方法。