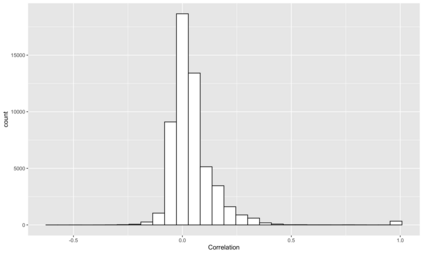
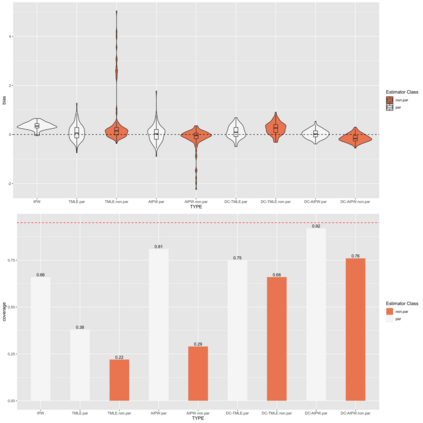
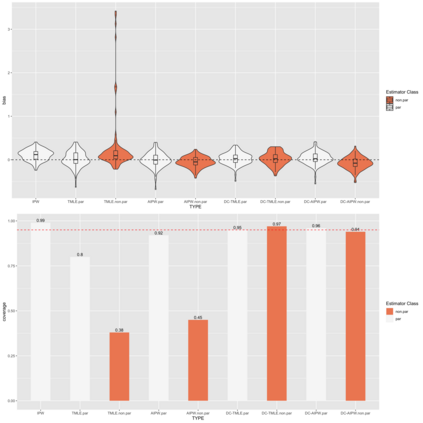
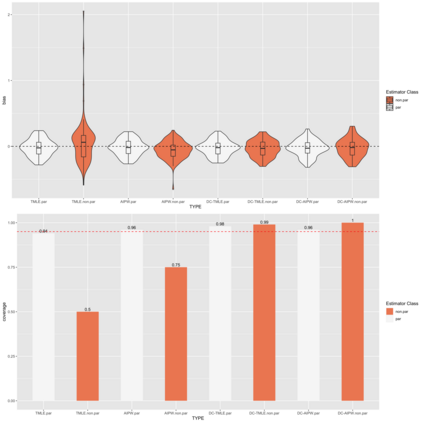
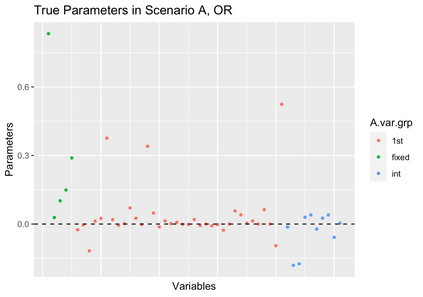
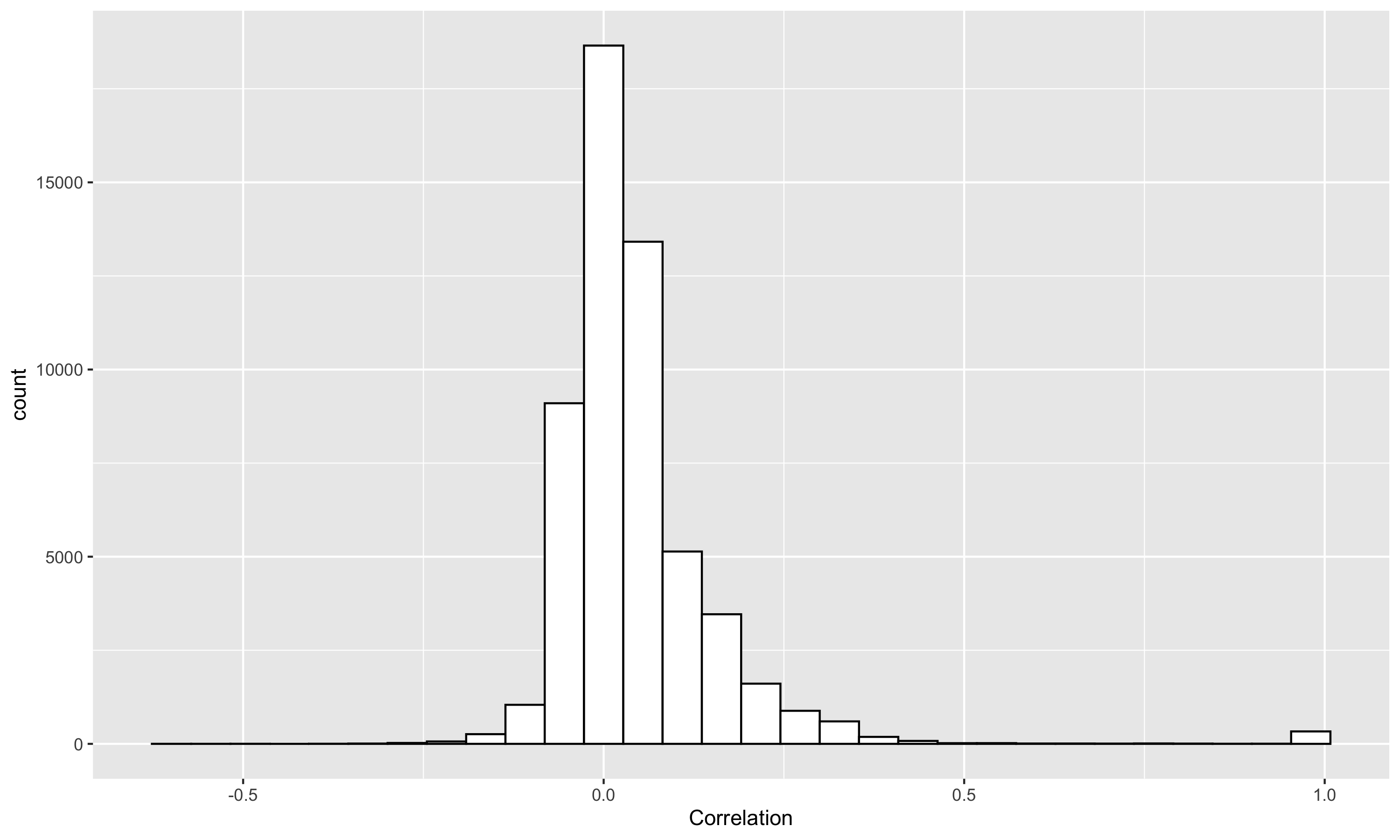
Modern efficient estimators such as AIPW and TMLE facilitate the application of flexible, non-parametric machine learning algorithms to improve treatment and outcome model fit, allowing for some model misspecification while still maintaining desired bias and variance properties. Recent simulation work has pointed to essential conditions for effective application including: the need for cross-fitting, using of a broad library of well-tuned, flexible learners, and sufficiently large sample sizes. In these settings,cross-fit, doubly robust estimators fit with machine learning appear to be clearly superior to conventional alternatives. However, commonly simulated conditions differ in important ways from settings in which these estimators may be most useful, namely in high-dimensional, observational settings where: costs of measurements limit sample size, high numbers of covariates may only contain a subset of true confounders, and where model misspecification may include the omission of essential biological interactions. In such settings, computationally-intensive and challenging to optimize cross-fit, ensemble learning-based estimators may have less of a practical advantage. We present extensive simulation results drawing data on 331 covariates from 1178 subjects of a multi-omic, longitudinal birth cohort while fixing treatment and outcome effects. We fit models under various conditions including under- and over- (e.g. excess orthogonal covariates) specification, and missing interactions using both state-of-the-art and less-computationally intensive (e.g. singly-fit,parametric) estimators. In real data structures, we find in nearly every scenario (e.g. model misspecification, single- or cross-fit- estimators), that efficient estimators fit with parametric learner out perform those that include non-parametric learners on the basis of bias and coverage.
翻译:AIPW 和 TMLE 等现代高效估测器(TMLE) 等现代有效估测器(AIPW 和 TMLE ) 有利于应用灵活、非参数的机器学习算法,以改善治疗和结果模型的适合性,允许某些模型的偏差特性,同时仍然保持理想的偏差和差异性。最近的模拟工作指出了有效应用的基本条件,包括:需要交叉安装,使用由良好、灵活学习者组成的广泛图书馆,以及足够大的样本大小。在这些环境中,与机器学习相匹配的超强估算器显然优于常规的替代方法。然而,通常模拟的条件与这些估测器可能最有用的环境有很大的不同,即高度、观测环境:测量成本限制样本大小、高差异量的共变异体数量可能包含一系列真实性研究者,而模型的偏差可能包含基本生物互动的遗漏。在这种环境中,计算密集和具有挑战性的挑战性估算器可能比常规的要差得多。 我们对这些估算结果进行了广泛的模拟,同时使用331 的不精确的比值的比值结构的比值的比值分析结果,, 包括每11 模型的模型的模型的比值的模型的模型下的结果。