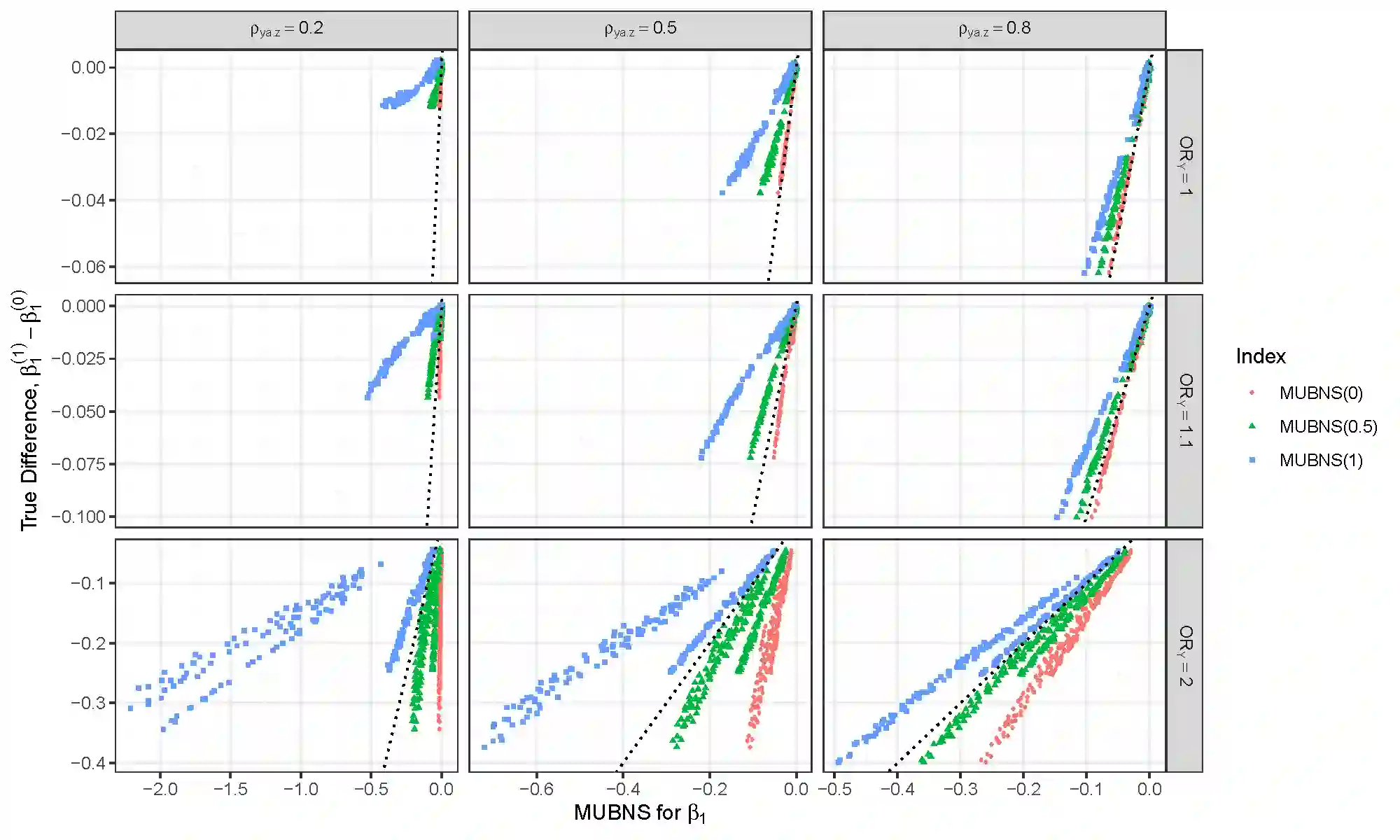
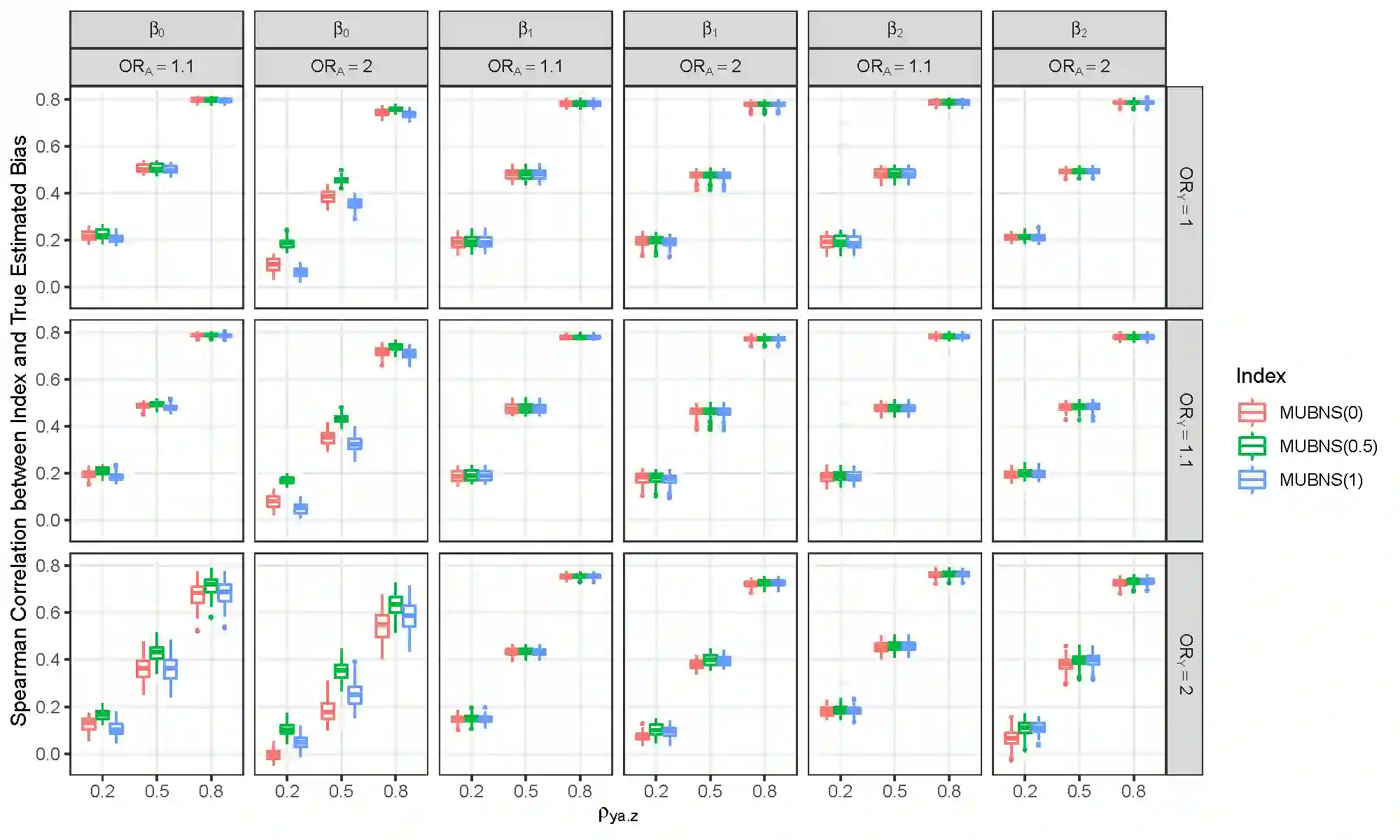
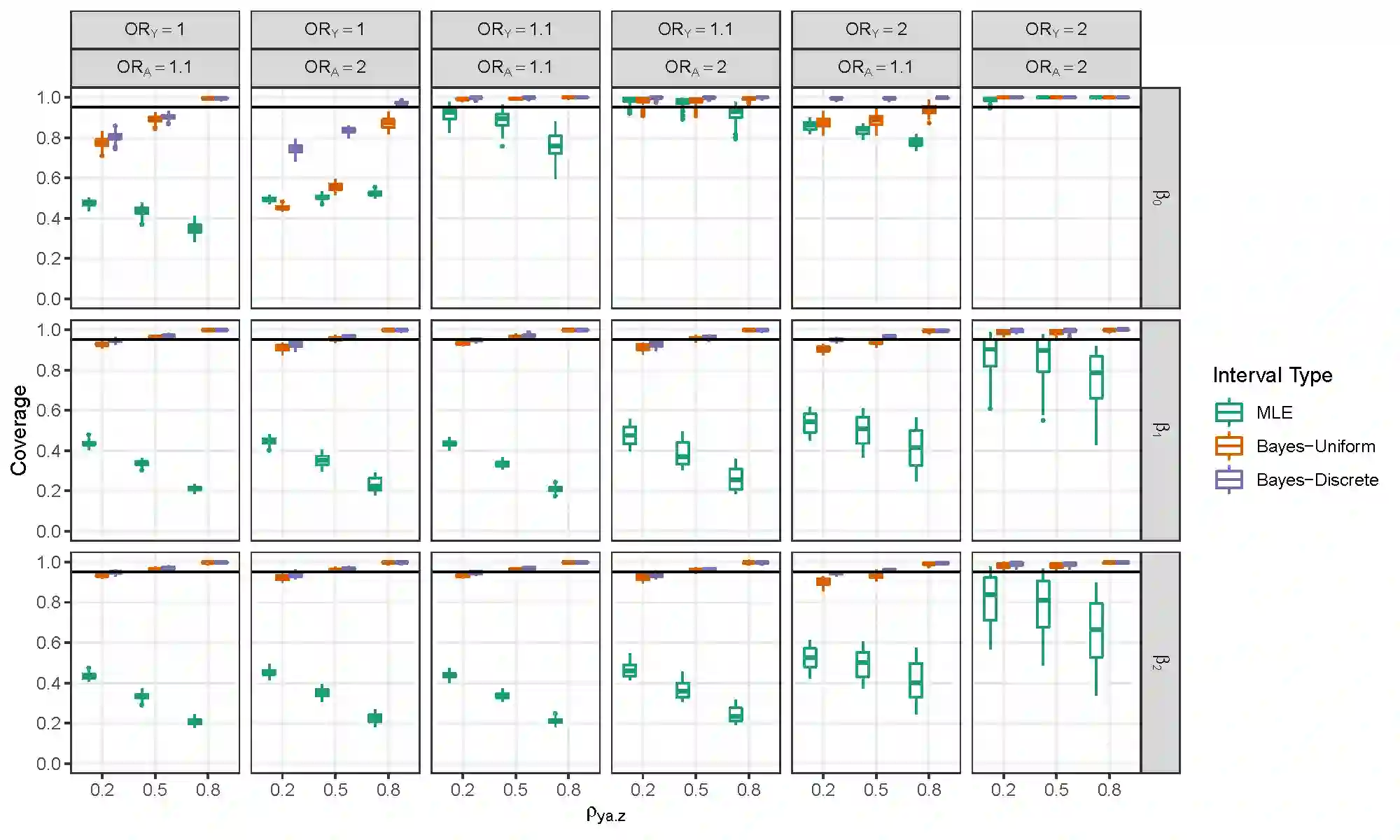
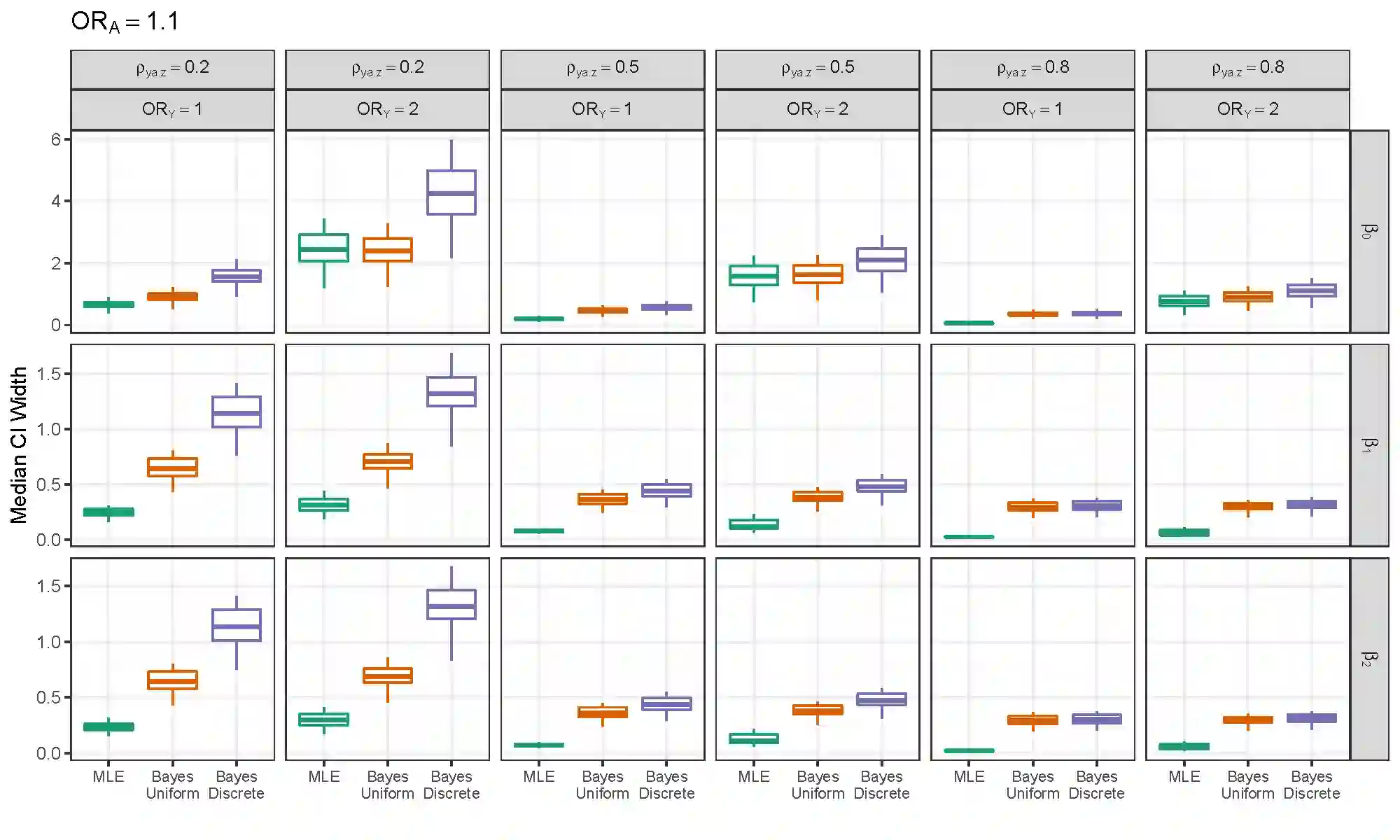
Selection bias is a serious potential problem for inference about relationships of scientific interest based on samples without well-defined probability sampling mechanisms. Motivated by the potential for selection bias in (a) estimated relationships of polygenic scores (PGSs) with phenotypes in genetic studies of volunteers, and (b) estimated differences in subgroup means in surveys of smartphone users, we derive novel measures of selection bias for estimates of the coefficients in linear and probit regression models fitted to non-probability samples, when aggregate-level auxiliary data are available for the selected sample and the target population. The measures arise from normal pattern-mixture models that allow analysts to examine the sensitivity of their inferences to assumptions about non-ignorable selection in these samples. We examine the effectiveness of the proposed measures in a simulation study, and then use them to quantify the selection bias in (a) estimated PGS-phenotype relationships in a large study of volunteers recruited via Facebook, and (b) estimated subgroup differences in mean past-year employment duration in a non-probability sample of low-educated smartphone users. We evaluate the performance of the measures in these applications using benchmark estimates from large probability samples.
翻译:选择偏差是一个严重的潜在问题,可以据以推断根据没有明确界定的概率抽样机制的样本而具有科学利益的关系。受以下因素的偏差潜在选择偏差的驱使,即:(a) 自愿者基因研究中多原计分(PGS)与苯型的估计关系,和(b) 智能电话用户调查中分组手段的估计差异,我们从对适合非概率抽样的线性和原生回归模型的系数的估计中得出新的选择偏差衡量尺度。当为选定的抽样和目标人群提供综合级辅助数据时。措施来自正常的模式混合模型,使分析人员能够对这些样本中不值得注意的选择进行判断的敏感性审查。我们在模拟研究中审查拟议措施的有效性,然后在对通过脸书征聘的志愿人员进行大规模研究时,用这些模型来量化选择偏差:(a) 对PGS-原生型关系的估计;以及(b) 在对低教育智能用户进行非概率抽样时,估计上一年平均雇用期限的分组差别。我们用这些基准估计数评估这些应用中的措施的概率。